My blogging setup with Emacs and Org Mode
Or “when you don’t have topics to write about, write about how you do your writing”. Ahem.
I like my blog workflow, it makes me want to return to writing more often, and because of this, I capture way more thoughts than I would usually do if I didn’t have a blog. However, there are a lot of ways to set up a blog, and when I was starting I was overwhelmed with options. There are a lot of posts with the title “my blogging setup with…” and most of these that I’ve seen are very shallow in detail. With this post, I would hope to explain things in a bit more detail, so people who’re interested in creating their own blog could use this post as an instruction, sort of. Or maybe it will be yet another post that will not be that helpful to anyone struggling like I did.
At least, I wish I’d found something like this when I was starting out. So today, I would like to describe my blogging setup in Emacs, tools I use outside of Emacs, and tweaks I made to make the process more automated. Let’s begin!
Hugo
There are a lot of various static site generators (SSG) available today: Jekyll, Pelican, 11ty, e.t.c. - there are many of them.
At the time, I was looking for something that I could use with Emacs’ Org Mode package because I really liked it, and a commonly suggested generator was Hugo.
It has limited support for .org file format, so I decided to try it.
Other than that, it is really fast, their template language is not hard and quite versatile, and there are a lot of themes to try.
I eventually made my own theme, so it is possible too.
I must say, that I haven’t tried other SSGs, Hugo immediately worked for me, so I have no real opinion on why you should prefer Hugo to, say, Jekyll - it just works for me. If you’re already using another static site generator, and it works for you, there’s no need to change it, unless you’re missing some features, possibly ones I will be going to talk about in this post.
So without further ado, let’s set up a new blog with Hugo!
Hugo setup
I’m using Fedora Linux, so in my case installing Hugo is one command away:
$ sudo dnf install hugo
I don’t think there’s anything else you’ll need to start blogging, so the setup is really easy. See the getting started guide to see all other installation options.
With the hugo command installed, we need a place, where we will store all blog-related files, let’s create a directory for it in the home directory:
$ mkdir ~/blog ; cd ~/blog
In order for Hugo to recognize this blog, it needs to have a certain file structure and a config file. We’ll also need a theme for the blog, as Hugo doesn’t come with a pre-built one:
$ git init .
$ git submodule add https://github.com/theNewDynamic/gohugo-theme-ananke.git themes/ananke
Now, we can create a config file.
A config file for Hugo uses the TOML format, and is called config.toml.
It has a quite simple structure, and there are standard things we need to take care in it:
baseurl = "/"
contentdir = "content"
publishdir = "public"
canonifyurls = true
relativeURLS = false
theme = "ananke"
title = "My awesome blog"
languageCode = "en-us"
summaryLength = 42
copyright = "copyright info, like license, year, author name, e.t.c."
[author]
name = "Your Name"
[params]
description = "Something about your blog"
showFooterCredits = true
math = false
useIcon = true
[outputFormats]
[outputFormats.RSS]
mediatype = "application/rss+xml"
baseName = "feed"
~/blog/config.toml
I think this is a bare minimum you’ll need to start, but there are more options you can set here, or even create your own ones.
There’s a comprehensive configuration section on Hugo’s site that you can refer to for more details.
I’ve left out some bits, so we’ll return to the config.toml file a bit later.
Right now let’s focus on the top of the file - there are two variables that interesting for us contentdir and publishdir.
The contentdir one is a place where hugo will take markdown files from, and render them to static html files put in the bublishdir.
We will not use both of these directly, but you can try by putting the following markdown file into posts directory inside the contentdir:
+++
title = "Hello there!"
author = ["Your Name"]
tags = ["some", "tags"]
draft = false
+++
General Kenobi
~/blog/content/posts/hello.md
Now we can build our blog and serve it on localhost with the hugo server command:
$ hugo server
Start building sites …
hugo v0.93.3+extended linux/amd64 BuildDate=unknown
| EN
-------------------+-----
Pages | 10
Paginator pages | 0
Non-page files | 0
Static files | 1
Processed images | 0
Aliases | 1
Sitemaps | 1
Cleaned | 0
Built in 108 ms
Watching for changes in /home/alist/blog/{content,themes}
Watching for config changes in /home/alist/blog/config.toml, /home/alist/blog/themes/ananke/config.yaml
Environment: "development"
Serving pages from memory
Running in Fast Render Mode. For full rebuilds on change: hugo server --disableFastRender
Web Server is available at //localhost:1313/ (bind address 127.0.0.1)
Press Ctrl+C to stop
It should look something like this:
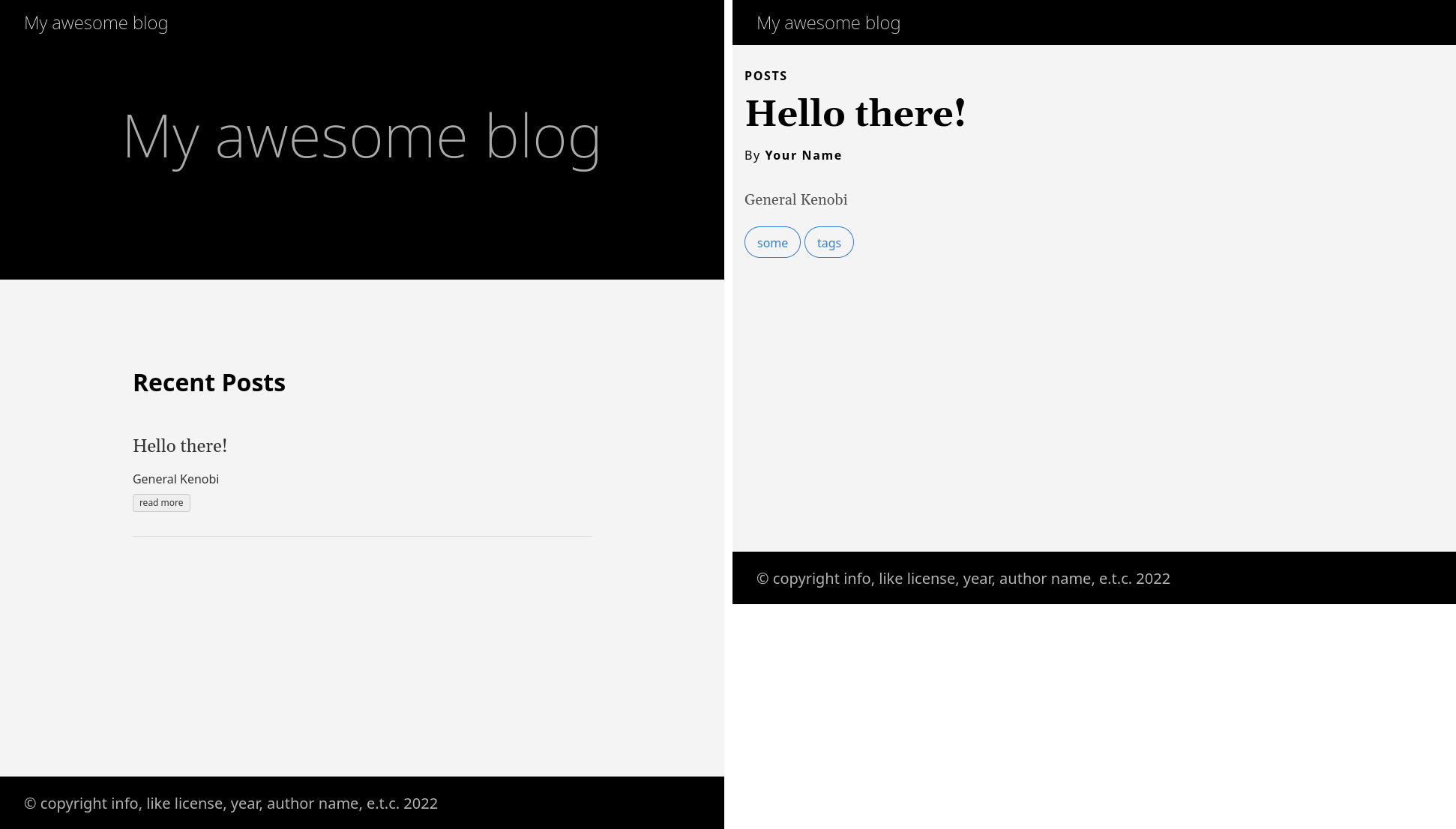
Figure 1: The blog homepage is on the left, and the post page is on the right
Well, maybe not the most beautiful result, but this is just for demonstration purposes. There are a lot of themes for Hugo, so you can choose any other you like.
And this is pretty much it - you can start blogging right away, just create a markdown file as shown above, and Hugo will take care of the rest. Except, I want to do it with Emacs and Org mode specifically, and if you do too, follow along.
Additional Hugo things
There are many other things Hugo can do. For example, you can create RSS feed for your blog, create alternative pages on your blog based on contents of your blog, e.t.c.
Some settings are dependent on the theme. So a lot of config options can be quite different from theme to theme, and it makes it a bit harder to try out other themes. When I was writing about choosing a new look for my blog earlier this year, it was a major obstacle for me, so my advice would be to find a theme you like as early as possible, until your blog grows with a lot of custom settings, and other tweaks. Well, it’s general advice - if you really will want to migrate to another theme you’ll do it no matter what, just know that it might be a bit problematic.
Speaking of the theme-specific stuff, for example, my blog theme has a support for links section, which I set up like this:
[[params.links]]
[[params.links.link]]
name = "Gitlab"
href = "https://gitlab.com/andreyorst/"
[[params.links.link]]
name = "Github"
href = "https://github.com/andreyorst/"
[[params.links.link]]
name = "Tags"
href = "/tags"
[[params.links.link]]
name = "Categories"
href = "/categories"
[[params.links.link]]
name = "Archive"
href = "/posts"
[[params.links.link]]
name = "About"
href = "/about"
This will not work for ananke, because it has its own notion of social-related links:
[[params.ananke_socials]]
name = "twitter"
url = "https://twitter.com/GoHugoIO"
So refer to the documentation of your theme of choice for this kind of stuff.
Also, note that some links in my config are pointing to statically generated pages, like /tags or /categories.
Hugo automatically will generate these if the theme has a support for them, or if you’ve created your own templates.
For instance, the ananke theme, we’re using for our example blog supports such, and if you will manually go to the localhost:1313/tags you will see a list of tags, generated from the post we’ve created.
Even though we’ve never created this page ourselves.
As I’ve mentioned this is done with the template language.
For example, here’s how the ananke theme handles creating this page:
<ul class="pa0">
{{ range .GetTerms "tags" }}
<li class="list di">
<a href="{{ .RelPermalink }}" class="link f5 grow no-underline br-pill ba ph3 pv2 mb2 dib black sans-serif">
{{- .LinkTitle -}}
</a>
</li>
{{ end }}
</ul>
There’s a lot to dig in, so instead of explaining everything here and now, I’ll point you to the documentation once again.
Yeah, I know, I’ve said it will be a comprehensive post, but I’m not going to write a full course on Hugo here.
It is an advanced stuff, and I didn’t know anything about that when I started, so you probably don’t need it too yet.
Just keep in mind that you can generate pages, and it is done by writing stuff in these {{ }} expressions.
Now, let’s get back on topic, and look at how we can do our blogging with the comfort of Emacs
Emacs
If you’re already an Emacs user, then great, you don’t need me to teach you how to install it, the packages, and so on. If you’re not an Emacs user, then this section is probably not for you. Two previous sections should be enough for a pretty decent blogging workflow with Markdown.
But in my setup, I’m using Org Mode instead of Markdown, for several reasons, which I won’t go into. And the only text editor that supports Org in its full capacity is Emacs. There are plugins for other text editors, like this one for VSCode, but they’re not even close to what Org mode can offer.
Org is not just a markup format, like many may think, it is actually an application within Emacs.
Editing .org document is like working in something like an office suite - you have things to format text, but you also get stuff like spreadsheets, and you can run code to manipulate spreadsheets data.
Org comes with a variety of backends for exporting it to other formats, e.g. to LaTeX, HTML, ODT, or even plain Markdown.
We’re going to install such backend for exporting to Hugo-compatible markdown.
Yes, Hugo uses a bit different Markdown, as there are a lot of so-called Markdown flavors, each with their own features, the most popular being GitHub-Flavored Markdown (or GFM for short). For us, it’s not a problem, because we will be writing in Org, and the ox-hugo package will take care of the rest.
ox-hugo
To install the ox-hugo package, use whatever you’re using to install packages.
Again, refer to the documentation if you’re not sure what to do.
I’m using straight.el to install packages, and use-package to manage configurations.
So in my case, the configuration for ox-hugo looks like this:
(use-package ox-hugo
:straight ( :host github
:repo "kaushalmodi/ox-hugo"
:branch "main")
:after ox)
Nothing special, yet.
With this installed, we can start using .org files in our blog instead of .md files, but there are two ways of doing it.
First one is to use a single .org file where all posts are stored together as headings.
Let’s call it post-per-subtree.
Second is to use separate .org files for each post, or post-per-file.
When I started this blog, I used the first approach, but as my blog grew bigger with more and more long posts with a lot of markup in them, images, LaTeX formulas, and other stuff, Emacs started struggling to edit this file. It wasn’t that bad, but spell-checking gave me a lot of hard time, given that it sometimes wanted to process the whole file for some reason. Still, unsatisfied with the results I’ve migrated my blog from post-per-subtree to post-per-file approach. This is another example of what you should decide pretty early on - it is possible to migrate, but it is a considerable amount of manual work. I had to move 611 posts from headings to files, set all frontmatter, and other stuff.
I, personally, would suggest you to use post-per-file approach, but this is just my experience. Ox-hugo’s docs actually suggest you to use post-per-subtree approach because it has some additional features, that you can’t get automatically when using post-per-file:
There are 2 major blogging flows that can be used with this package:
- One post per Org subtree (preferred)
- Export only the current post Org subtree, or
- Export all valid Hugo post subtrees in a loop.
- One post per Org file
- This works but you won’t be able to leverage Org-specific benefits like tag and property inheritance, use of TODO states to translate to post draft state, auto weight calculation for pages, taxonomies and menu items, etc.
See the Org Capture Setup page to see how to quickly create new posts.
I’ve used tagged headings and properties, and TODO items as well, so once I’ve migrated these features were gone.
However, I don’t really miss these for a few reasons.
TODO items are handy, but really only for local workflow.
Hugo can skip building pages for posts that are marked with draft property.
When setting the pipeline for building blog on something like GitHub/GitLab pages you usually want this.
When working locally, however, when you want to see how your text looks rendered, you can include draft posts by specifying -D argument to hugo command.
I could use draft by manually specifying it in the frontmatter, but in actuality, I just don’t commit exported .md files for my draft posts.
So the lack of TODO markers is not a problem in my workflow, as I usually work on a single post at a time.
It may be different for you.
The lack of tags or properties is not a problem for me either. A bit later I’ll show you my solution for tags, which I like even more than the old approach. As for properties, I didn’t use them that much, so it may vary from user to user.
Writing an example post in .org
Let’s try writing a post similarly to how we did with Markdown, but now with Org and ox-hugo.
I will briefly touch both approaches for blogging flow, as described by ox-hugo, but later on I will use post-per-file.
Let’s create a blog.org file in the root directory or our blog:
#+title: My awesome blog
#+author: Your Name
#+hugo_auto_set_lastmod: t
#+hugo_base_dir: .
#+hugo_section: .
* Posts
:properties:
:export_hugo_section: posts
:end:
** Hello There! :some:tags:
:properties:
:export_file_name: hello
:end:
General Kenobi
** Other post
:properties:
:export_file_name: other-post
:end:
Keep bloggin
~/blog/blog.org
Now, with this file in place and ox-hugo installed and loaded, you can put the cursor on one of the headings and press C-c C-e shortcut (or call org-export-dispatch function), and you should see a menu, something like this:
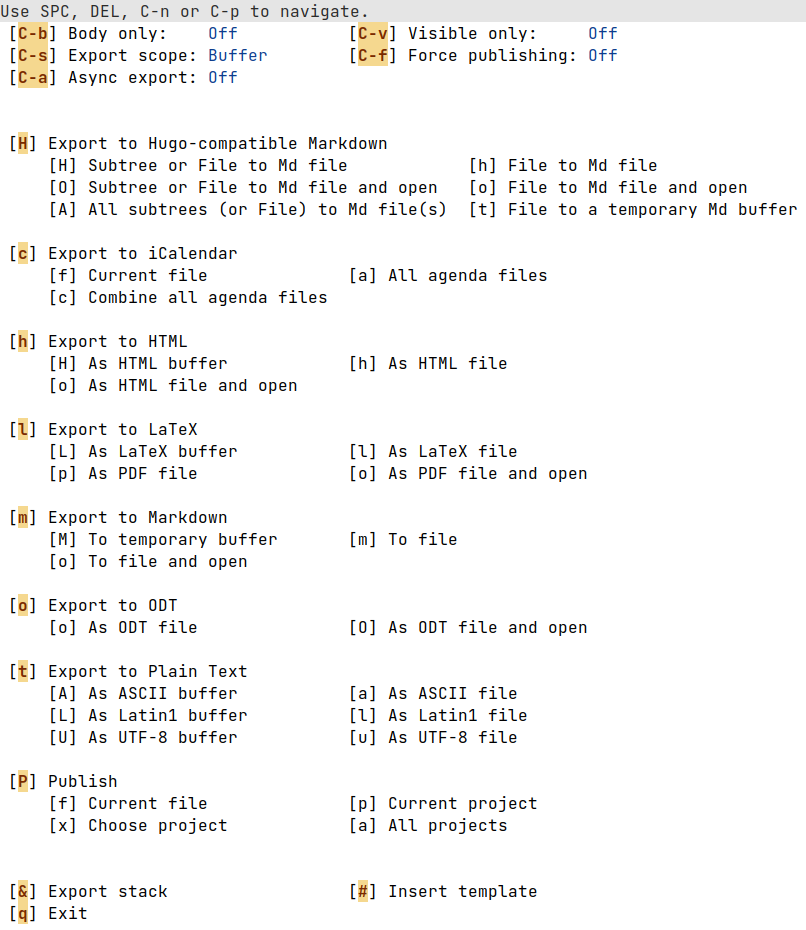
Press H, followed by another H, and ox-hugo will generate an .md file based on the :properties: section under the heading.
Repeat for all headings, or press H A to export all headings.
The generated file will be almost identical to what we’ve written by hand before, with the only difference being that ox-hugo will add the lastmod property, indicating the last time this file was edited.
So if you’re exporting all subtrees beware that all lastmod entries may be updated.
To do the same thing with post-per-file approach, we’ll need a directory to store .org files in:
#+hugo_base_dir: ../
#+hugo_section: posts
#+hugo_auto_set_lastmod: t
#+title: Hello there!
#+hugo_tags: some tags
General Kenobi
~/blog/post/hello.org
For this to work you need to specify the hugo_base_dir to point to the root of the blog.
In case of file-per-subtree approach we had the blog.org file in the root directory, so there the base directory was set to ./.
Since now, we’re inside the ~/blog/post/ directory, the base directory is ../.
Just a small detail to be aware of.
This mostly takes care on the general blogging workflow with ox-hugo.
You either create a post per file in a dedicated directory, or use a single file for all posts.
Simple as that.
The top section of the file, consisting of #+ things is a frontmatter, that is exported to the .md file.
You can add custom elements to it, and specify other things like date, categories and so on.
I’m showing the bare minimum needed to get started, so you’ll need to explore other features by yourself.
Automating things with Emacs
Once I migrated to post-per-file approach, I quickly realized how painful it is to write the frontmatter each time by hand.
So, following the advice from ox-hugo I’ve created a sophisticated org-capture template that takes care of a lot of things.
I’ve created a so-called local feature, or inline package, if you will, for my Emacs configuration, with a lot of stuff related to my blogging workflow.
It’s a bit big, so I’ve hidden it, as I will go into details in a bit.
But you probably can just copy and paste this thing into your config, and it should work, if you have use-package.
A local blog package.
(use-package blog
:commands (blog-publish-file
blog-generate-file-name
blog-read-list-items)
:preface
(defvar blog-capture-template
"#+hugo_base_dir: ../
#+hugo_section: posts
#+hugo_auto_set_lastmod: t
#+options: tex:dvisvgm
#+macro: kbd @@html:<kbd>$1</kbd>@@
#+title: %(format \"%s\" blog--current-post-name)
#+date: %(format-time-string \"%Y-%m-%d %h %H:%M\")
#+hugo_tags: %(blog-read-list-items \"Select tags: \" 'blog-tags)
#+hugo_categories: %(blog-read-list-items \"Select categories: \" 'blog-categories)
#+hugo_custom_front_matter: :license %(format \"%S\" blog-license)
%?"
"Org-capture template for blog posts.")
(defcustom blog-tags nil
"A list of tags used for posts."
:type '(repeat string)
:group 'blog)
(defcustom blog-categories nil
"A list of tags used for posts."
:type '(repeat string)
:group 'blog)
(defcustom blog-directory "~/blog"
"Location of the blog directory for org-capture."
:type 'string
:group 'blog)
(defcustom blog-license ""
"Blog license string."
:type 'string
:group 'blog)
(defvar blog--current-post-name nil
"Current post name for org-capture template.")
(defun blog-read-list-items (prompt var)
"Completing read items with the PROMPT from the VAR.
VAR must be a quoted custom variable, which will be saved if new
items were read by the `completing-read' function."
(let ((items (eval var)) item result)
(while (not (string-empty-p item))
(setq item (string-trim (or (completing-read prompt items) "")))
(unless (string-empty-p item)
(push item result)
(setq items (remove item items))
(unless (member item (eval var))
(customize-save-variable var (sort (cons item (eval var)) #'string<)))))
(string-join result " ")))
(defun blog-title-to-fname (title)
(thread-last
title
(replace-regexp-in-string "[[:space:]]" "-")
(replace-regexp-in-string "-+" "-")
(replace-regexp-in-string "[^[:alnum:]-]+" "")
downcase))
(defun blog-generate-file-name (&rest _)
(let ((title (read-string "Title: ")))
(setq blog--current-post-name title)
(find-file
(file-name-concat
(expand-file-name blog-directory)
"posts"
(format "%s-%s.org"
(format-time-string "%Y-%m-%d")
(blog-title-to-fname title))))))
(defun blog-publish-file ()
"Update '#+date:' tag, and rename the currently visited file.
File name is updated to include the same date and current title."
(interactive)
(save-match-data
(let ((today (format-time-string "%Y-%m-%d"))
(now (format-time-string "%h %H:%M")))
(save-excursion
(goto-char (point-min))
(re-search-forward "^#\\+date:.*$")
(replace-match (format "#+date: %s %s" today now)))
(let* ((file-name (save-excursion
(goto-char (point-min))
(re-search-forward "^#\\+title:[[:space:]]*\\(.*\\)$")
(blog-title-to-fname (match-string 1)))))
(condition-case nil
(rename-visited-file
(format "%s-%s.org" today
(if (string-match
"^[[:digit:]]\\{4\\}-[[:digit:]]\\{2\\}-[[:digit:]]\\{2\\}-\\(.*\\)$"
file-name)
(match-string 1 file-name)
file-name)))
(file-already-exists nil))
(save-buffer)))))
(provide 'blog))
This may look as a giant blob of weird looking code (because it is) so let’s dive into it.
First things first, this is an use-package directive for a non-existent feature blog.
It may make some people question things, so the first thing you need to know is that the :preface block runs before everything else, and at the end of it there is a (provide 'blog) call.
So it works like a package, even though it is a part of the init.el file.
The first ting it does is creating a capture template:
(defvar blog-capture-template
"#+hugo_base_dir: ../
#+hugo_section: posts
#+hugo_auto_set_lastmod: t
#+options: tex:dvisvgm
#+macro: kbd @@html:<kbd>$1</kbd>@@
#+title: %(format \"%s\" blog--current-post-name)
#+date: %(format-time-string \"%Y-%m-%d %h %H:%M\")
#+hugo_tags: %(blog-read-list-items \"Select tags: \" 'blog-tags)
#+hugo_categories: %(blog-read-list-items \"Select categories: \" 'blog-categories)
#+hugo_custom_front_matter: :license %(format \"%S\" blog-license)
%?"
"Org-capture template for blog posts.")
This template is then bound to the capture dispatch menu. As you can see it takes care of the frontmatter creation, as well as supplying some other info, such as date, post title, tags, e.t.c.
Most of this stuff is taken from custom variables, defined afterwards:
(defcustom blog-tags nil
"A list of tags used for posts."
:type '(repeat string)
:group 'blog)
(defcustom blog-categories nil
"A list of tags used for posts."
:type '(repeat string)
:group 'blog)
(defcustom blog-directory "~/blog"
"Location of the blog directory for org-capture."
:type 'string
:group 'blog)
(defcustom blog-license ""
"Blog license string."
:type 'string
:group 'blog)
You can use Custom to set these variables to values that are meaningful to your setup.
Next, there’s a function for reading a list of tags or categories from the respecting lists:
(defun blog-read-list-items (prompt var)
"Completing read items with the PROMPT from the VAR.
VAR must be a quoted custom variable, which will be saved if new
items were read by the `completing-read' function."
(let ((items (eval var)) item result)
(while (not (string-empty-p item))
(setq item (string-trim (or (completing-read prompt items) "")))
(unless (string-empty-p item)
(push item result)
(setq items (remove item items))
(unless (member item (eval var))
(customize-save-variable var (sort (cons item (eval var)) #'string<)))))
(string-join result " ")))
It is a bit sketchy, as it mutates the custom file, populating it with new tags, because I find it handy. No need to remember all tags, when you can choose existing ones via a completion menu, and automatically remember new ones. This function works for any custom variable that is a list of strings, so it may be handy for other purposes as well.
Now, when I create posts, I want them to follow a certain format for a file names.
This format is year-month-day-post-name.org.
The following functions take care of this:
(defun blog-title-to-fname (title)
(thread-last
title
(replace-regexp-in-string "[[:space:]]" "-")
(replace-regexp-in-string "-+" "-")
(replace-regexp-in-string "[^[:alnum:]-]+" "")
downcase))
(defun blog-generate-file-name (&rest _)
(let ((title (read-string "Title: ")))
(setq blog--current-post-name title)
(find-file
(file-name-concat
(expand-file-name blog-directory)
"posts"
(format "%s-%s.org"
(format-time-string "%Y-%m-%d")
(blog-title-to-fname title))))))
The first one is responsible for replacing all space characters with dashes, and removing consecutive dashes.
It also removes all non alpha-numeric characters from the name.
The second one is used during capturing.
It sets the blog--current-post-name for the given title, creates a file, and names it accordingly to the format I’ve mentioned.
This mostly takes care about capturing, but there are often situations when I’ve updated the date of the post (because I was working on it for several days, and capture stored the initial one), or when I updated a title, and I want file-name to reflect that:
(defun blog-publish-file ()
"Update '#+date:' tag, and rename the currently visited file.
File name is updated to include the same date and current title."
(interactive)
(save-match-data
(let ((today (format-time-string "%Y-%m-%d"))
(now (format-time-string "%h %H:%M")))
(save-excursion
(goto-char (point-min))
(re-search-forward "^#\\+date:.*$")
(replace-match (format "#+date: %s %s" today now)))
(let* ((file-name (save-excursion
(goto-char (point-min))
(re-search-forward "^#\\+title:[[:space:]]*\\(.*\\)$")
(blog-title-to-fname (match-string 1)))))
(condition-case nil
(rename-visited-file
(format "%s-%s.org" today
(if (string-match
"^[[:digit:]]\\{4\\}-[[:digit:]]\\{2\\}-[[:digit:]]\\{2\\}-\\(.*\\)$"
file-name)
(match-string 1 file-name)
file-name)))
(file-already-exists nil))
(save-buffer)))))
This function does a basic replace of the date with the current date, and renames the visited file accordingly. So it is meant to be used only when editing a file that is a post in the blog.
With this set of functions, and a capture template I don’t need anything more for a comfortable blogging experience.
And compared to post-per-subtree flow, I don’t need to write any :properties: blocks, with export file name that uses my date-based format, which I previously did manually, but now I just call blog-publish-file once I’ve decided that the post is ready.
Last but not least, the settings for org-capture:
(use-package org-capture
:defer t
:custom
(org-directory blog-directory)
(org-capture-templates `(("p" "Post" plain
(function blog-generate-file-name)
,blog-capture-template
:jump-to-captured t
:immediate-finish t))))
This capture template is the only one I’m using right now, and it essentially only needed to fill all the parts of the template, and then jump to the captured file.
Spell-checking
Another thing worth mentioning is checking text for spelling mistakes.
I actually use two tools in Emacs: the inbuilt flyspell package, and the langtool.el package, which is a client for the language tool server.
Flyspell is enough to check most spelling mistakes in regular words, though it often doesn’t know a lot of tech-related stuff. It doesn’t require any setup, except the installation of the dictionary, which is then detected automatically.
LanguageTool is more about writing style, catching the wrong usage of times, and other such mistakes. It mostly works without any setup, though, I had to fix a small bug in its implementation. Here’s my config:
(use-package langtool
:straight t
:commands (langtool-check-buffer langtool-check-buffer@fix-narrowing)
:when (and langtool-installation-dir
(file-exists-p langtool-installation-dir))
:preface
(defcustom langtool-installation-dir nil
"Path to the local installation of langtool."
:type '(choice (const :tag "not installed" nil)
string)
:tag "Langtool installation directory"
:group 'langtool)
(defvar langtool-args
(let ((ngrams (expand-file-name "ngrams-en-20150817"
langtool-installation-dir)))
(when-let (file-exists-p ngrams)
(list (concat "--languageModel " ngrams)))))
:custom
(langtool-language-tool-jar
(expand-file-name "languagetool-commandline.jar"
langtool-installation-dir))
(langtool-java-user-arguments langtool-args)
(langtool-language-tool-server-jar
(expand-file-name "languagetool-server.jar"
langtool-installation-dir))
(langtool-http-server-host "localhost")
(langtool-server-user-arguments langtool-args)
:config
(define-advice langtool-check-buffer (:around (fn &optional lang) fix-narrowing)
(save-mark-and-excursion
(unless (use-region-p)
(push-mark)
(push-mark (point-max) nil t)
(goto-char (point-min)))
(funcall fn lang))))
For the best results, I highly recommend downloading the ngram data archive (8 GB), uncompressing it to the installation directory, and passing it as an argument for langtool.
That way, it will find more mistakes.
I’ve considered using Grammarly, and as far as I know, it has better detection, based on an AI model, but it also requires registration, and it is a paid service, while langtool can be used locally, and it is an open source solution.
You can always try both and pick the one you liked more.
Or just use both of them, though they sometimes think differently.
My workflow
So, the workflow in my blog looks like this:
M-x org-capture RET,p- fire up capture menu, and select the post entry with thepkey;- Enter posts title;
- Fill in tags and categories;
- Edit;
- Re-publish, if I’ve changed the title, or the date has changed;
- Export to Hugo Markdown;
- Commit and push, wait for the deploy to finish.
Here’s a recording of me doing this:
I like how tag reading interface prevents me from accidentally adding the same tags by removing already added ones from the list. And I can always correct mistakes, like a wrong title, and don’t do any manual file renaming. Overall this process is pleasant, I must say, and I like it more than with the post-per-subtree approach.
There’s the last part, the deployment of the blog to, in my case, GitLab pages.
I’m using a rather simple .gitlab-ci.yml file, that simply builds the site for me every time I push:
---
image: registry.gitlab.com/pages/hugo/hugo_extended:latest
pages:
script:
- hugo --minify
artifacts:
paths:
- public
only:
- main
Simple as that.
I went with GitLab because I wanted a private repository - I don’t think there’s a need for other people to see my drafts, and I don’t really want to keep the git history clean, to be honest. The blog repo is like a pile of thoughts I throw into it, and then selectively publish ones that I think worth it.
So, if you’ve followed this post’s examples, the whole ~/blog directory by now should look something like that:
$ tree -a ~/blog
├── blog.org # if you want to go post-per-subtree
├── posts # if you want to go post-per-file
│ └── hello.org
├── config.toml
├── content
│ └── posts
│ └── hello.md
├── .git
│ └── ...
├── .gitlab-ci.yml
├── .gitmodules
└── themes
└── ananke
└── ...
Running hugo server in this directory should give you a preview of the blog, and you can experiment with templates, themes, and other stuff without actually deploying it.
Also, when editing .org files, and re-exporting them via ox-hugo, Hugo will detect changes and live reload the active page if needed.
It’s really handy, and you can actually use it as a live preview by putting a browser side by side to Emacs, or by using something like eww.
Should you start blogging?
Yes, I believe so.
Even if your blog will not be as big as some of your favorite blogs, you’ll notice a lot of benefits after some amount of time. As I mentioned at the beginning of this post, I started capturing a lot more thoughts after I started writing things in 2020. There were a lot of various thoughts running through my head before 2020, but I never gave them time to get a shape. Now if I feel like something might be interesting, I grab my laptop and start writing. Even if I will later discard the idea, and trash all text I’ve written, it’s still a win, because I understood that the idea wasn’t really good, or that I can’t write about it just yet.
So in my opinion, blogging can improve your ability to give thoughts shape and form. There’s a famous quote by Leslie Lamport:
If you’re thinking without writing, you only think you’re thinking
I think it’s true. Quite often I can think about a problem hard enough, and feel like I’m not able to come to some solution. Then I open a chat with my coworker and start writing a long message that I’m going to send them, with a thorough problem description, and things I’ve already tried. By the middle of such a message, usually, I already know the answer to my question or I’m figuring out a solution, so I just don’t send the message. You can think about it as the “Rubber Duck Debugging” method, but without a duck, and instead of talking to a toy I’m writing a draft message to a coworker.
So yeah, if you ever had a thought that you maybe should have a blog, then absolutely go for it. And I hope that this post can be helpful to make the process easier.
Thanks for reading!
-
many of them are “hidden” ↩︎