Advent of Code 2021 - full event
Originally these were all separate posts, but this generated way too many entries in the feed, so I’ve decided to put these into a single one. I’ve kept the content as is, and this very post originally contained the following message:
This is just a quick update on the upcoming posts schedule.
Last year I’ve decided to participate in Advent of Code 2020. It was a bit late decision, as I’ve started doing tasks around December 14th, and was burnt out by the pace I had to maintain to keep up with the others. It didn’t go so well, and I only completed tasks for the first 14 days, the last submission was on December 28, and I’ve got 28 gold stars total1. It’s a shame that I couldn’t finish the event in time, but it was fun, and this year I’ve decided not to repeat the same mistake and join the event when it starts.
For those unfamiliar with AOC, this event usually has some pretty interesting puzzles, and some kind of story, that progresses each day, and each task leads to another task and the story continues. And since the tasks are pretty interesting, I’ve decided to start a small series of posts, where I express how I’ve approached the task, and what tricks I’ve used to accomplish it.
I hope that I’ll be able to maintain the pace, and publish one post per day through the first 25 days of December until the event is finished. My blog is mostly built around Fennel and Emacs, but I’ll be doing the tasks in Clojure, as I feel that I’m giving this language less time than I should. I’ve also thought about using another language, like Erlang/Elixir or Common Lisp, but decided to go with Clojure, because learning a new language, and going through puzzles, while writing posts about both topics, and doing normal life stuff is a bit too much to handle. So Clojure it is.
I’m not sure if I’ll be able to finish all puzzles, but we’ll see how it goes. If you’re a programmer, and you never participated in AOC, I highly recommend you to - it’s great fun and a good challenge!
That’s all for now, see you on December 1st!
Everything that follows, was taken from the posts and adjusted a bit for a better reading experience. Enjoy!
Welcome to the series of posts on this year’s Advent of Code event!
This year, to keep myself motivated, I decided to write a small post each day, in which I’ll describe the way I’ve approached this day’s AOC puzzle.
As I’ve mentioned I’ll be solving puzzles in Clojure, (usually) formatting the code as can be seen in the REPL.
So if you see a code block that starts with day1>, it means that we’re inside the REPL, and in a day1 namespace.
And, without further ado, let’s begin!
Day 1 - Sonar Sweep
The first task is about calculating the rate at which the depth is increasing. Should be pretty simple!
For the given example input:
199
200
208
210
200
207
240
269
260
263
We need to count the number of times a depth measurement increases from the previous measurement.
This means, that we need to check if 200 is greater than 199, then that 208 is greater than 200, and so on.
Sounds like a job for reduce!
Let’s write such algorithm, and only partially supply the input:
user> (ns day1)
nil
day1> (reduce (fn [res [current next]]
(+ res (if (> next current) 1 0)))
0
[[199 200] [200 208]])
2
This correctly returns 2, now let’s feed it the whole input!
But we need to regroup the input first, so there will be a group of two for each number.
Luckily we have a function just for that, called partition:
day1> (partition 2 1 [199 200 208 210 200 207 240 269 260 263])
((199 200)
(200 208)
(208 210)
(210 200)
(200 207)
(207 240)
(240 269)
(269 260)
(260 263))
Sweet!
Let’s put our reduce into a function that does this transformation, and plug this input into it!
day1> (defn part-1 [input]
(reduce (fn [res [current next]]
(+ res (if (> next current) 1 0)))
0
(partition 2 1 input)))
#'day1/part-1
day1> (part-1 [199 200 208 210 200 207 240 269 260 263])
7
And it returns the correct result for the test input! Now we can try with a real one.
I’ll not be sharing the whole input in the blog, but you can always see it in my GitHub repo for AoC.
First, we need a function, that will read and parse the input file:
day1> (require '[clojure.string :as str])
nil
day1> (defn- read-input []
(->> "inputs/day1"
slurp
str/split-lines
(map #(Integer/parseInt %))))
I’m putting all input files into the inputs directory, named after the respecting day of the event.
In this case, it’s inputs/day1.
We slurp this file, and split-lines so there is a sequence of strings, each representing a line of the file.
Then we map over it with an anonymous function, that uses Integer/parseInt a Java method that parses the string as an integer.
This may throw a NumberFormatException of course, but I trust that the author of the event provides a valid input.
Now, let’s plug this input into our part-1 function:
day1> (part-1 (read-input))
1215
And we surely get the right answer!
I’ve also realized that instead of reduce we can use filter and just count the amount of remaining numbers, like this:
day1> (defn part-1 [input]
(->> input
(partition 2 1)
(filter (partial apply <))
count))
#'day1/part-1
day1> (part-1 (read-input))
1215
It yields the same result but is much more concise. I’ll keep this solution.
Time for part two.
Part two
Part two changes how the calculations are done a bit.
Now we need to do a sliding sum of groups of three.
This means, that for the test input, we need to check if the sum of the first three numbers, in our case these are 199, 200, 208, is smaller than the sum of three numbers, starting from the second number: 200, 208, 210.
This grouping is again can be achieved by partitioning:
day1> (partition 3 1 [199 200 208 210 200 207 240 269 260 263])
((199 200 208)
(200 208 210)
(208 210 200)
(210 200 207)
(200 207 240)
(207 240 269)
(240 269 260)
(269 260 263))
Now we just need to sum these subsequences with a map:
day1> (->> [199 200 208 210 200 207 240 269 260 263]
(partition 3 1)
(map (partial apply +)))
(607 618 618 617 647 716 769 792)
And we can apply our part-1 function on the new input:
day1> (->> [199 200 208 210 200 207 240 269 260 263]
(partition 3 1)
(map (partial apply +))
(part-1))
5
Again, we get a correct answer for the test input, so let’s put this into a function, and pass it a real one:
day1> (defn part-2 [input]
(->> input
(partition 3 1)
(map (partial apply +))
part-1))
#'day1/part-2
day1> (part-2 (read-input))
1150
And we get a correct answer!
Day 1 thoughts
This wasn’t hard, but no need to relax yet. More complex tasks are surely on the way!
I hope you’ve liked this short post of me describing the thought process for solving this day’s task. I’ll (hopefully) be publishing such posts each day, up to the event’s end. We’ll see how far I’ll manage to get!
Day 2 - Dive!
This task is about navigating a submarine. If I remember correctly, something similar was in the last year’s AoC. This year, we’re given a set of instructions in the following form:
forward 5
down 5
forward 8
up 3
down 8
forward 2
Where forward increases the horizontal position, and up and down decrease and increase depth respectively.
Our goal is to compute the end coordinate and then compute its product, after following all these commands.
Let’s write a function that accepts the current position, direction, and the amount we need to move as a vector.
day1> (ns day2)
nil
day2> (defmulti move (fn [_ [direction _]] direction))
#'day2/move
I’ve decided to use a multimethod here. Multimethods in Clojure are simple functions, that dispatch to a concrete body based on the dispatching function. This can be done by hand in any other language, in Clojure, the dispatching process is automated for you. I’ve chosen a multimethod without any particular reason, I just thought that it will be handy if we will be able to add new behavior to already existing function.
So let’s write movement methods. Since our input is a string, we will dispatch on strings, representing the direction:
day2> (defmethod move "forward" [[x y] [_ amount]] [(+ x amount) y])
#multifn[move 0x23444b67]
day2> (defmethod move "up" [[x y] [_ amount]] [x (- y amount)])
#multifn[move 0x23444b67]
day2> (defmethod move "down" [[x y] [_ amount]] [x (+ y amount)])
#multifn[move 0x23444b67]
We’re simply expressing the movement rules from the task. Let’s try it on the example input:
day2> (-> [0 0]
(move ["forward" 5])
(move ["down" 5])
(move ["forward" 8])
(move ["up" 3])
(move ["down" 8])
(move ["forward" 2]))
[15 10]
This gives us the correct coordinate and multiplying its x and y parts produces the expected result of 150.
Now we need to read the real input and transform it into such form: [[direction amount] ...], but this time, let’s write a proper parse-long function:
day2> (ns aoc-commons)
nil
aoc-commons> (defn parse-long [s]
(if (string? s)
(try
(Long/valueOf s)
(catch NumberFormatException _ nil))
(throw (IllegalArgumentException.
(format "Expected string, got %s" (some-> s class .getName))))))
I’m putting it to the aoc-commons namespace, so I could reuse it in another days.
Luckily this function will soon be available in the next Clojure release.
aoc-commons> (in-ns 'day2)
#namespace[day2]
day2> (require '[commons :refer [parse-long]]
'[clojure.string :as str])
nil
day2> (->> "inputs/day2"
slurp
str/split-lines
(map #(str/split % #"\s+"))
(map #(update % 1 parse-long))
(take 3))
(["forward" 7] ["forward" 9] ["forward" 9])
Seems to work so far - let’s put it into the function read-input.
Now we need to automate the computation we did earlier.
Again, similarly to the previous day’s task, reduce is the function we need:
day2> (defn part-1 [input]
(->> input
(reduce move [0 0])
(apply *)))
#'day2/part-1
Let’s plug the input, and see if it produces the correct answer:
day2> (part-1 (read-input))
2036120
And this is indeed the answer we’re expected to get! Let’s move to part two.
Part two
Last year, we misinterpreted the movement instructions, which required us to rework the algorithm a bit, and accord for the rotation.
This year the situation is very similar.
Turns out that up and down change the aim parameter, and forward moves accordingly to it, by multiplying aim to the amount we need to move forward and adding it to the depth.
Let’s rewrite the moving function:
day2> (defn move-and-aim [[x y aim] [direction amount]]
(case direction
"up" [x y (- aim amount)]
"down" [x y (+ aim amount)]
"forward" [(+ x amount) (+ y (* aim amount)) aim]))
#'day2/move-and-aim
Since we know, that we won’t need to expand our movement, and we only needed to change how we move.
Multimethod was overkill after all, but, well, you never know.
The main difference between this way of doing the dispatch, and when using the multimethod, is that we can extend the behavior of the multimethod without modifying the existing code.
In the case of this function, if we were to add, say, backward, we would need to change the source code of this function.
With multimethods, we would just add another defmethod.
But in the case of this particular situation there’s no need for it, so case will do.
Let’s plug it into reduce:
day2> (->> (read-input)
(reduce move-and-aim [0 0 0])
(apply *))
2196947010440
And… this is not the correct result. Why? let’s see, we’re producing seemingly correct coordinates on the test input:
day2> (reduce move-and-aim
[0 0 0]
[["forward" 5] ["down" 5] ["forward" 8] ["up" 3] ["down" 8] ["forward" 2]])
[15 60 10]
And multiplying 15 and 60 produces the correct answer for the example input.
So why it is not correct when applied to the real input?
Let’s plug the test input into our previous code:
day2> (->> [["forward" 5] ["down" 5] ["forward" 8] ["up" 3] ["down" 8] ["forward" 2]]
(reduce move-and-aim [0 0 0])
(apply *))
9000
It is indeed incorrect.
But now I see the issue, I forgot that we’re multiplying all elements in the resulting vector, and now this vector has a third element - the aim.
And in the case of the test input, it is equal to 10, thus the result is ten times bigger than the expected one.
Let’s remove it before computing the result with take:
day2> (defn part-2 [input]
(->> input
(reduce move-and-aim [0 0 0])
(take 2)
(apply *)))
#'day2/part-2
day2> (part-2 (read-input))
2015547716
Now, that’s the correct result.
Day 2 thoughts
The task wasn’t hard.
I’ve made a simple mistake at the end when I’ve computed the product of depth and horizontal coordinate and forgot to remove the aim from the equation.
Multimethod was a bit overkill, but I think it’s still a nice way to show that the same thing can be achieved in two ways, and one is a more general version of another.
Now, when I think of it, it seems that I tend to use tuples far more than dictionaries.
For example, I could use an associative structure with :depth, and :horizontal keys in it, and completely avoid the bug with multiplication, and any calls to apply for that matter.
Maybe I should think more in terms of associative structures for the next tasks.
Other than that, the task was pretty straightforward, and I’m curious to see what’s coming next.
Day 3 - Binary Diagnostic
This task is once again themed around the submarine, we’re using to find the keys. But today we need to perform diagnostics of the submarine systems. The diagnostics came as the following example input:
00100
11110
10110
10111
10101
01111
00111
11100
10000
11001
00010
01010
It’s a list of binary numbers, and we need to work with those via a specific set of rules.
First, we need to take only the first column of each row, and count how many zeroes and ones are there to compute the most common bit.
In the case of the first column, there are seven ones, and five zeroes, and the most common bit is 1.
We need to repeat that for each column, and the resulting bits will be the number we’re looking for.
Let’s prepare the data.
For the data format, I think a sequence of vectors of integers will do. We can transform the test input string to such format as follows:
day2> (ns day3)
nil
day3> (require '[aoc-commons :refer [parse-long]]
'[clojure.string :as str])
nil
day3> (->> "00100\n11110\n10110\n10111\n10101\n01111\n00111\n11100\n10000\n11001\n00010\n01010"
str/split-lines
(map seq)
(map #(mapv (fn [c] (parse-long (str c))) %)))
([0 0 1 0 0]
[1 1 1 1 0]
[1 0 1 1 0]
[1 0 1 1 1]
[1 0 1 0 1]
[0 1 1 1 1]
[0 0 1 1 1]
[1 1 1 0 0]
[1 0 0 0 0]
[1 1 0 0 1]
[0 0 0 1 0]
[0 1 0 1 0])
day3> (def test-data *1)
#'day3/test-data
OK, this appears to look correct. Now, we need to write an algorithm that will count bits in the given column:
day3> (->> test-data
(map #(get % 0))
sort
(split-with (partial = 0))
(map count))
(5 7)
This should do it.
We map the get function over each of the vectors to get the 0th bit.
Then, we sort the result, so all zeroes go before all ones, and split it with the (partial = 0) function, which gives us the result of [(0 0 0 0 0) (1 1 1 1 1 1 1)].
Finally, we map the count function, to compute the amount of each bit, producing the final result of (5 7).
But it’s hard to remember what these numbers are, e.g. you can’t say if there’s 5 zeroes of 5 ones, by looking at the code.
Your only hint is a call to sort, which sorts zeroes before ones, but it’s hard to grasp at a glance, so let’s put this into a table.
We also need to make 0 argument to get a parameter, so here’s our function:
day3> (defn count-bits [bit-n input]
(->> input
(map #(get % bit-n))
sort
(split-with (partial = 0))
(map count)
(zipmap [:ones :zeroes])))
#'day3/count-bits
Finally, to get the most common bit we need to map this function for every index in our vectors.
To obtain the size of the vector we can count the first vector from the input, and use it to create a range, that we will map over:
day3> (defn most-common-bits [input]
(->> input
first
count
range
(map #(count-bits % input))))
#'day3/most-common-bits
Calling this function with our test input produces the following sequence of maps:
day3> (most-common-bits test-data)
({:ones 5, :zeroes 7}
{:ones 7, :zeroes 5}
{:ones 4, :zeroes 8}
{:ones 5, :zeroes 7}
{:ones 7, :zeroes 5})
This appears to be correct, but we’re missing the final step of converting this to a vector of the most common bits.
To do this, we just need one extra map over this list, that compares ones and zeroes, and chooses the most common one:
day3> (defn most-common-bits [input]
(->> input
first
count
range
(map #(count-bits % input))
(map (fn [{:keys [zeroes ones]}]
(if (> zeroes ones) 1 0)))))
#'day3/most-common-bits
day3> (most-common-bits test-data)
(1 0 1 1 0)
This number is the correct one for the given example input. But it’s not it yet.
We need to compute another number, which consists of the lest common bits.
We could change the predicate in the most-common-bits function, and create the least-common-bits function, but it would be a waste.
All we need is to flip all bits in the number we got:
day3> (defn flip-bit [b]
(if (= b 0) 1 0))
#'day3/flip-bit
day3> (map flip-bit *2)
(0 1 0 0 1)
And this is indeed the correct number.
Finally, we need to compute their product. To do so, we need to parse the binary representation into a decimal first. Let’s concatenate our lists to string and use default Java method for parsing:
day3> (* (Long/parseLong (str/join '(1 0 1 1 0)) 2)
(Long/parseLong (str/join '(0 1 0 0 1)) 2))
198
This is the correct result. Let’s just wrap the whole thing into a function, and test with the real input:
day3> (defn read-input []
(->> "inputs/day3"
slurp
str/split-lines
(map seq)
(map #(mapv (fn [c] (parse-long (str c))) %))))
#'day3/read-input
day3> (defn part-1 [input]
(let [gamma (most-common-bits input)
epsilon (map flip-bit gamma)]
(* (Long/parseLong (str/join gamma) 2)
(Long/parseLong (str/join epsilon) 2))))
#'day3/part-1
day3> (part-1 (read-input))
3885894
And we got the correct result! Time for part two.
Part two
Whoa.. that’s a lot of text! And numbers… Anyway, let’s see what’s up with all of this new information.
The idea is that we need to compute two more numbers, but now, we need to filter out some numbers based on a condition. To get the first number, we need to determine the most common bit for the given position and keep only such rows, that contain that number in the same position. The second number is exactly the same, except we need to use the least common bit. Should be pretty easy. Let’s start by writing a function, that determines which bit we need to use as criteria for filtering:
day3> (defn bit-criteria [type {:keys [ones zeroes]}]
(case type
:oxygen (if (< zeroes ones) 0 1)
:CO2 (if (< zeroes ones) 1 0)))
#'day3/bit-criteria
Interestingly enough, the task explicitly mentions, that if we got the same amount of ones and zeroes, we need to choose 1 for oxygen, and 0 for CO2.
I haven’t accounted for this case in the first part, and I haven’t even thought about it, to be frank.
And even though the logic above doesn’t have an explicit check for this case as well, it works perfectly along with the rules:
day3> (bit-criteria :oxygen {:zeroes 4 :ones 4})
1
day3> (bit-criteria :CO2 {:zeroes 4 :ones 4})
0
I’m using the same format as returned by the count-bits function here.
Now, all we need is to implement the algorithm:
day3> (defn calculate [type input]
(let [total (count (first input))] ; ①
(loop [n 0
numbers input]
(let [bits (count-bits n numbers)
criteria (bit-criteria type bits) ; ②
res (filter #(= (get % n) criteria) numbers)] ; ③
(if (= 1 (count res))
(first res)
(when (< n total)
(recur (inc n) res)))))))
#'day3/calculate
That’s a lot of code, but the job this function does is pretty simple.
We compute the total amount of bits we need to check at ①.
Then we go into the loop, where we will check each bit n, starting from 0.
We count all bits in a given position and compute the criteria ②.
Finally, we filter only those rows, that have the same bit as the criteria bit in the position of n ③.
At this point, we have all rows that match the criteria. If we only got 1 row, that’s the result we need. If not, we go into the next iteration with the current amount of rows and check the next bit.
Let’s plug this into a function, and see if it’s correct for the test input:
day3> (defn part-2 [input]
(let [oxygen (calculate :oxygen input)
co2 (calculate :CO2 input)]
(* (Long/parseLong (str/join oxygen) 2)
(Long/parseLong (str/join co2) 2))))
#'day3/part-2
day3> (part-2 test-data)
230
And it is correct! Now we can check this with the real input:
day3> (part-2 (read-input))
4375225
And we get another gold star, as this is the right answer for my input!
Day 3 thoughts
Definitively was a bit harder than the previous day, but still a lot of fun! After I looked at my solution at the end of the day, I’ve realized that it wasn’t necessary to convert strings to numbers, as I could compare everything that way. But it wasn’t too much extra works, so that’s that.
Overall, I think my code is a bit complex, but I’m not sure how to improve it.
Funnily enough, while writing this I’ve noticed that the implementation of most-common-bits was wrong, as I’ve used < instead of >, but the resulting answer was still correct, as the second number is just the inverse of the first one.
Day 4 - Giant Squid
The winter just has started, and it’s already the first weekend! The time goes pretty fast this time of the year. I guess it’s because there’s so much going on! There’s always some kind of rush at the end of the year at work. Everyone is preparing for the upcoming holidays, purchasing gifts, and buying delicious food and drinks upfront. I’m also preparing for the upcoming talk at this year’s Fennel conf. And of course, there’s Advent of Code to spice everything up, he-he!
Speaking of which, here’s our next game!
Today we’re got ourselves into some wild situation - a giant squid has attached itself to the outside of your submarine and wants to play bingo!
I’m sure that everyone is familiar whit this kind of game, though this particular one usually has several names in various countries. The closest alternative, widely known in my country is Lotto (Italiano)2.
The test puzzle input looks like this:
7,4,9,5,11,17,23,2,0,14,21,24,10,16,13,6,15,25,12,22,18,20,8,19,3,26,1
22 13 17 11 0
8 2 23 4 24
21 9 14 16 7
6 10 3 18 5
1 12 20 15 19
3 15 0 2 22
9 18 13 17 5
19 8 7 25 23
20 11 10 24 4
14 21 16 12 6
14 21 17 24 4
10 16 15 9 19
18 8 23 26 20
22 11 13 6 5
2 0 12 3 7
The first row determines the order in which we need to mark numbers on the board. The twist is that we have several boards, and we need to find the first one that wins. Let’s parse this input into a data structure that will allow us to work with it.
day3> (ns day4)
nil
day4> (require '[aoc-commons :refer [parse-long]]
'[clojure.string :as str])
nil
day4> (def test-input "7,4,9,5,11,17,23...") ; rest of the input is omitted
#'day4/test-input
First, let’s parse the first line:
day4> (defn parse-draws [lines]
(map parse-long (str/split lines #",")))
#'day4/parse-draws
day4> (parse-draws (-> test-input str/split-lines first))
(7 4 9 5 11 17 23 2 0 14 21 24 10 16 13 6 15 25 12 22 18 20 8 19 3 26 1)
Next we should parse the boards. I’m thinking of vector of vectors of numbers, like this:
[[ 2 13 17 11 0]
[ 8 2 23 4 24]
[21 9 14 16 7]
[ 6 10 3 18 5]
[ 1 12 20 15 19]]
For a single board. And since we have many boards, we would have another vector around them. Let’s write a function that does that:
day4> (defn prepare-row [row]
(mapv parse-long
(-> row
str/trim
(str/split #"\s+"))))
#'day4/prepare-row
day4> (defn parse-boards [lines]
(->> lines
(remove empty?)
(partition 5)
(mapv (partial mapv prepare-row))))
#'day4/parse-boards
day4> (parse-boards (->> test-input str/split-lines (drop 1)))
[[[22 13 17 11 0]
[8 2 23 4 24]
[21 9 14 16 7]
[6 10 3 18 5]
[1 12 20 15 19]]
[[3 15 0 2 22]
[9 18 13 17 5]
[19 8 7 25 23]
[20 11 10 24 4]
[14 21 16 12 6]]
[[14 21 17 24 4]
[10 16 15 9 19]
[18 8 23 26 20]
[22 11 13 6 5]
[2 0 12 3 7]]]
Now, we just need to combine the two and return a table, where we will have our draws, and boards under the respecting keys:
day4> (defn read-input []
(let [lines (->> #_#_"inputs/day4" ; We'll need this when we
slurp ; will work with real input
test-input
str/split-lines)]
{:draws (parse-draws (first lines))
:boards (parse-boards (drop 1 lines))}))
#'day4/read-input
day4> (read-input)
{:draws
(7 4 9 5 11 17 23 2 0 14 ...),
:boards
[[[22 13 17 11 0]
[8 2 23 4 24]
[21 9 14 16 7]
[6 10 3 18 5]
[1 12 20 15 19]]
...]}
Parsing the input itself was a neat task, isn’t it? Now, we can play Bingo!
To mark the number on a board, I’ll be replacing the number with a nil.
Anything but nil will do, of course, but we don’t really care about numbers we’ve marked, so it’s OK to replace them with something that we can easily distinguish.
day4> (defn mark-board [number board]
(mapv #(mapv (fn [x] (if (= number x) nil x)) %) board))
#'day4/mark-board
day4> (mark-board 5 [[1 2 3]
[4 5 6]
[7 8 9]])
[[1 2 3] [4 nil 6] [7 8 9]]
I hope you get the idea.
Next, we need to check if the board won.
The board wins, when any of the rows have all numbers marked, which in our case means, a vector with every element equal to nil.
However, the board also wins, when any of the columns are marked, which means we need to check columns as well.
But since this is a simple matrix, we can just rotate it, and check if any of the rows, that previously were columns are fully marked.
To rotate the board we can use this trick:
day4> (apply mapv vector [[1 2 3]
[4 5 6]
[7 8 9]])
[[1 4 7]
[2 5 8]
[3 6 9]]
As you can see, the board is rotated!
This happens because when we apply the mapv function to a vector of vectors we essentially get this:
(mapv vector [1 2 3] [4 5 6] [7 8 9])
This means that vector will be called with 1, 4, and 7, then with 2, 5, and 8, and finally whit 3, 6, 9, producing a new matrix, which is a rotated version of the original.
Knowing that, we can implement the check-board function as follows:
day4> (defn rotate [board]
(apply mapv vector board))
#'day4/rotate
day4> (defn check-board [board]
(when (or (some (partial every? nil?) board)
(some (partial every? nil?) (rotate board)))
board))
#'day4/check-board
day4> (check-board [[1 2]
[3 4]])
nil
day4> (check-board [[nil nil]
[3 4]])
[[nil nil] [3 4]]
day4> (check-board [[nil 2]
[nil 4]])
[[nil 2] [nil 4]]
As you can see, this function returns nil when the board doesn’t have any winning rows or columns, and returns the board itself, if it has any rows or columns that are fully marked.
Finally, we need a function, that will draw the numbers, and fill our boards, checking if any of the boards won. Should be pretty simple:
day4> (defn find-winning-board [draws boards]
(loop [[number & draws] draws
boards boards]
(let [boards (mapv (partial mark-board number) boards)]
(if-let [winning-board (some check-board boards)]
{:win-number number
:board winning-board}
(recur draws
boards)))))
#'day4/find-winning-board
Now, we can feed this function our draws and boards, and see which board wins, and which number was the last one:
day4> (defn calculate-result [{:keys [win-number board]}]
(* win-number
(->> board
flatten
(filter number?)
(apply +))))
#'day4/calculate-result
day4> (defn part-1 [{:keys [draws boards]}]
(->> boards
(find-winning-board draws)
(calculate-result)))
#'day4/part-1
day4> (part-1 (read-input))
4512
This is the correct result for the example input from the puzzle. Trying it on the real input yields another correct result, which means we did everything correctly. Let’s see what twist waits for us in part two!
Part two
The gimmick of the second part is that we want to let the giant squid win this time. Perhaps it would be pleased and leave our submarine.
In order to do that, we just need to find the board that wins the last. This is a relatively small change from our existing algorithm - we need to keep all non-winning boards, and repeat games with them until nothing is left. Once no boards are left, we can take the last board from the previous game, and it will be the board that wins last:
day4> (defn find-last-winning-board [draws boards]
(loop [[number & draws] draws
boards boards]
(let [boards (mapv (partial mark-board number) boards)
non-winning (remove check-board boards)]
(if (empty? non-winning)
{:win-number number
:board (last boards)}
(recur draws
non-winning)))))
#'day4/find-last-winning-board
day4> (defn part-2 [{:keys [draws boards]}]
(->> boards
(find-last-winning-board draws)
(calculate-result)))
#'day4/part-2
day4> (part-2 (read-input))
1924
The result is correct for the test data, and when tried with the real one, it remains correct, which is great!
Day 4 thoughts
This task was daunting at first, given that the giant squid could drag the submarine anywhere in the ocean, and we’d be completely lost, but we’ve made it through! When I saw the boards, I’ve immediately thought: “yeah, we’re going to rotate some matrix today”, but then I’ve realized it’s quite easy to do. The code feels a bit too imperative for my liking, but I don’t see how I can improve it right now. And it works so for now, I think that will do.
Day 5 - Hydrothermal Venture
We’ve reached a field of hydrothermal vents on the ocean floor, and to avoid all of these to prevent our submarine from drowning. Our example puzzle input looks like this:
0,9 -> 5,9
8,0 -> 0,8
9,4 -> 3,4
2,2 -> 2,1
7,0 -> 7,4
6,4 -> 2,0
0,9 -> 2,9
3,4 -> 1,4
0,0 -> 8,8
5,5 -> 8,2
These are the x,y coordinates mapped to another x,y coordinates, which determine where the vent starts and ends.
Our first task requires us to find which vents overlap, considering only horizontal vents.
I wonder what will wait for us in part two.
So, for the example input, the diagram that shows which vents overlap looks like this:
.......1..
..1....1..
..1....1..
.......1..
.112111211
..........
..........
..........
..........
222111....
Each 1 means that there’s a vent, and 2 means that two vents overlap.
Let’s write an input parsing function:
day5> (ns day5)
nil
day5> (require '[aoc-commons :refer [parse-long]]
'[clojure.string :as str])
nil
day5> (defn parse-coordinates [line]
(let [[_ x1 y1 x2 y2]
(re-matches #"(\d+),(\d+)\s+->\s+(\d+),(\d+)" line)]
[[(parse-long x1) (parse-long y1)]
[(parse-long x2) (parse-long y2)]]))
#'day5/parse-coordinates
Now, we can define the example input, and the read-input function:
day5> (def example-input
"0,9 -> 5,9
8,0 -> 0,8
9,4 -> 3,4
2,2 -> 2,1
7,0 -> 7,4
6,4 -> 2,0
0,9 -> 2,9
3,4 -> 1,4
0,0 -> 8,8
5,5 -> 8,2")
#'day5/example-input
day5> (defn read-input []
(->> #_"inputs/day5"
#_slurp
example-input
str/split-lines
(map parse-coordinates)))
#'day5/read-input
With that, we can get to work.
First, we need to keep only non-diagonal lines:
day5> (defn keep-non-diagonal [coordinates]
(filter (fn [[[x1 y1] [x2 y2]]]
(or (= x1 x2) (= y1 y2)))
coordinates))
#'day5/keep-non-diagonal
Next, we can build the lines. Since our lines are either horizontal or vertical, we can use a simple list comprehension to build them:
day5> (defn build-line [[[x1 y1] [x2 y2]]]
(let [[x1 x2] (sort [x1 x2])
[y1 y2] (sort [y1 y2])]
(for [x (range x1 (inc x2))
y (range y1 (inc y2))]
[x y])))
#'day5/build-line
Now, we need some kind of data structure, where we can keep all lines, and compute their overlapping parts.
Luckily for us, Clojure comes with an amazing library for data manipulation and transformation and has exactly the function we need.
This function is called frequencies.
It accepts a collection and counts how many there are entries for each element of the collection.
For example:
day5> (frequencies "ваыв")
{\в 2, \а 1, \ы 1}
You can see that the letter в is associated with 2, and it is exactly the amount of times this letter appeared in the string.
We can apply that to our vent coordinates.
Let’s write a reducing function:
day5> (defn mark-line [field line]
(let [fr (frequencies line)]
(merge-with (fnil + 1) field fr)))
#'day5/mark-line
day5> (defn mark-lines [field lines]
(reduce mark-line field lines))
#'day5/mark-lines
To illustrate how it works let’s use it with some fake coordinates:
day5> (mark-lines {} (map build-line [[[0 0] [0 5]]
[[2 0] [2 5]]
[[0 2] [5 2]]]))
{[2 2] 2,
[0 0] 1,
[2 3] 1,
[2 5] 1,
[0 5] 1,
[4 2] 1,
[5 2] 1,
[0 3] 1,
[2 4] 1,
[0 2] 2,
[2 0] 1,
[0 4] 1,
[2 1] 1,
[1 2] 1,
[3 2] 1,
[0 1] 1}
You can see that there are two overlapping vents for this input at points [2 2] and [0 2].
We can illustrate this better by writing a render function:
day5> (defn render [size points]
(let [field (vec (repeat size (vec (repeat size "."))))]
(->> points
(reduce (fn [field [[x y] val]]
(assoc-in field [x y] (str val)))
field)
(apply map vector)
(map str/join)
(map (partial str ";; "))
(str/join "\n")
println)))
#'day5/render
day5> (render 10 (mark-lines {} (map build-line [[[0 0] [0 5]]
[[2 0] [2 5]]
[[0 2] [5 2]]])))
;; 1.1.......
;; 1.1.......
;; 212111....
;; 1.1.......
;; 1.1.......
;; 1.1.......
;; ..........
;; ..........
;; ..........
;; ..........
nil
Finally, we need to calculate the number of entries greater than 1.
Let’s wrap everything into a function:
day5> (render 10 (create-field (read-input)))
;; .......1..
;; ..1....1..
;; ..1....1..
;; .......1..
;; .112111211
;; ..........
;; ..........
;; ..........
;; ..........
;; 222111....
nil
day5> (part-1 (read-input))
5
This produces the correct answer for the test input and by changing the input to the real one we get another correct answer. Now, let’s do this including the diagonal lines?
Part two
And, yes, part two really is about diagonal lines! Should be pretty straightforward.
We need a function that builds a diagonal line:
day5> (defn build-diagonale-line [[[x1 y1] [x2 y2]]]
(when (= (Math/abs (- x1 x2)) (Math/abs (- y1 y2)))
(let [xdir (if (> 0 (- x2 x1)) -1 1)
ydir (if (> 0 (- y2 y1)) -1 1)]
(loop [line [[x1 y1]]]
(let [[x y] (last line)]
(if (and (not= x x2) (not= y y2))
(recur (conj line [(+ x xdir) (+ y ydir)]))
line))))))
#'day5/build-diagonale-line
This is a total mess, but it works.
First, we determine if a pair of coordinates is strictly diagonal.
This is achieved with the ( (Math/abs (- x1 x2)) (Math/abs (- y1 y2)))= expression.
Next, if the line is diagonal, we check if the coordinates are in the correct order.
Finally, we loop, incrementing the starting position until we reach the end coordinate.
However, this function only accounts for the diagonal lines. Luckily, we’ve already created a function that creates a field with horizontal and vertical lines, so we can just merge two. Here’s an illustration:
day5> (let [input (read-input)]
(->> input
(keep build-diagonale-line)
(mark-lines (create-field input))
(render 10)))
;; 1.1....11.
;; .111...2..
;; ..2.1.111.
;; ...1.2.2..
;; .112313211
;; ...1.2....
;; ..1...1...
;; .1.....1..
;; 1.......1.
;; 222111....
nil
This looks exactly like the diagram from the task! Here’s the final solution:
day5> (defn part-2 [input]
(->> input
(keep build-diagonale-line)
(mark-lines (create-field input))
vals
(filter #(> % 1))
count))
#'day5/part-2
day5> (part-2 (read-input))
12
And it works on the real input as well. Great!
Day 5 thoughts
The second part of the task gave me some trouble initially, as I couldn’t figure out the correct way to compute diagonals. But after I’ve figured it out, it was pretty straightforward to complete!
I really like how Clojure comes with a lot of functions in the standard library for data manipulation and functional programming.
For example, another thing that you may haven’t noticed was the use of fnil.
It’s a special function, that accepts a function, and the default value, and returns a nil safe variant of the original function.
In case of the mark-line function, I’ve use (fnil + 1) which effectively created a + function that uses 1 if it gets a nil as a first argument.
Paired with frequencies and merge-with this made it really trivial to find all intersections.
Day 6 - Lanternfish
New task!
Today we’re watching how a massive school of glowing lanternfish swims past our submarine.
There are a lot of them, so their reproduction rate must be growing really fast, or, as the task explicitly mentions, exponentially fast.
Our task is to find out how many of the species there will be after 80 days, based on these rules:
- Each fish is represented as a number of days before reproduction, for example,
3,4,3,1,2 - Each day we subtract
1from such counter:2,3,2,0,1 - Each time a fish goes below
0it’s counter get’s reset to6, and a new fish added to the list with the counter value of8:1,2,1,6,0,8
After 18 days we’ll get such generation: 6,0,6,4,5,6,0,1,1,2,6,0,1,1,1,2,2,3,3,4,6,7,8,8,8,8, total of 26 fish.
Now, this seems to grow very fast, but let’s play dumb and solve this directly following these rules. First, as usual, let’s parse the input:
day5> (ns day6)
nil
day6> (require '[aoc-commons :refer [parse-long]]
'[clojure.string :as str])
nil
day6> (def example-input "3,4,3,1,2")
#'day6/example-input
day6> (defn read-input []
(map parse-long
(-> #_#_"inputs/day6"
slurp
example-input
str/trim-newline
(str/split #","))))
#'day6/read-input
Now, we can write a function that will tick each fish:
day6> (defn tick [generation]
(map dec generation))
#'day6/tick
day6> (tick (read-input))
(2 3 2 0 1)
day6> (tick *1)
(1 2 1 -1 0)
You can see that it doesn’t do any special logic regarding negative values.
We handle these in the populate function:
day6> (defn populate [generation]
(concat (map #(if (neg? %) 6 %) generation)
(repeat (count (filter neg? generation)) 8)))
#'day6/populate
day6> (populate (tick (read-input)))
(2 3 2 0 1)
day6> (populate (tick *1))
(1 2 1 6 0 8)
day6> (populate (tick *1))
(0 1 0 5 6 7 8)
As can be seen, after first tick no new fish were added, but on the next tick, populate changed fourths fish to 6, and added a new fish of 8.
Finally, we need a function that will wait a certain amount of days, effectively looping through these steps:
day6> (defn wait [days generation]
(if (= days 0)
generation
(recur (dec days) (->> generation tick populate))))
#'day6/wait
day6> (wait 18 (read-input))
(6 0 6 4 5 6 0 1 1 2 6 0 1 1 1 2 2 3 3 4 6 7 8 8 8 8)
day6> (count *1)
26
As you can see, it yields the correct result. Yay! Let’s check with 80 days!
day6> (count (wait 80 (read-input)))
5934
It works, of course it does.
Now let’s plug our real input and wait…
day6> (time (count (wait 80 (read-input))))
"Elapsed time: 1998.554897 msecs"
372300
Not too bad! This solution grants us the first gold start of the current day. Let’s see what awaits us in part two.
Part two
The only change is that we need to compute 256 days instead of 80.
Should be easy, right?
day6> (count (wait 256 (read-input)))
C-c C-c
day6>
OK, it doesn’t work. In fact, it doesn’t work even with the example input. Let’s see how fast the required time grows:
day6> (doseq [n (range 20 140 10)]
(print (str ";; " n ": "))
(time (count (wait n (read-input))))
nil)
;; 20: "Elapsed time: 14.215826 msecs"
;; 30: "Elapsed time: 26.630702 msecs"
;; 40: "Elapsed time: 55.405953 msecs"
;; 50: "Elapsed time: 142.670344 msecs"
;; 60: "Elapsed time: 322.692136 msecs"
;; 70: "Elapsed time: 762.395619 msecs"
;; 80: "Elapsed time: 1909.748014 msecs"
;; 90: "Elapsed time: 4356.629415 msecs"
;; 100: "Elapsed time: 10715.898879 msecs"
;; 110: "Elapsed time: 31755.26834 msecs"
;; 120: "Elapsed time: 109995.207696 msecs"
;; 130: "Elapsed time: 349632.859801 msecs"
nil
Plotting this with GNUPlot shows the following graph:
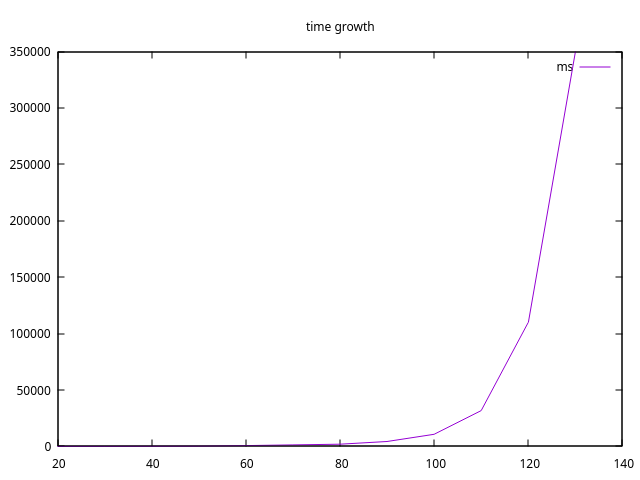
It indeed looks like exponential growth, so we need another approach. Calculating this on a modern PC with enough RAM and fast enough CPU is theoretically possible, I guess, but I’d not try that myself. It’d be a waste of CPU time and electricity.
Let’s look at our first generation again: 3,4,3,1,2.
We have five fish, and on the next day, there still will be five fish, as there’s no fish with a counter of 0.
Let’s group today’s fish by their counter:
day6> (frequencies [3 4 3 1 2])
{3 2,
4 1,
1 1,
2 1}
So you can see that the total sum of values from this map equals 5, which is a total fish count.
On the next generation this remains the same:
day6> (frequencies (populate (tick [3 4 3 1 2])))
{2 2,
3 1,
0 1,
1 1}
But on the next generation we get this:
day6> (frequencies (populate (tick (populate (tick [3 4 3 1 2])))))
{1 2,
2 1,
6 1,
0 1,
8 1}
We got ourselves a new fish with a counter of 8, and now the total sum equals 6.
By the end of day 18 there are 26 fish:
day6> (frequencies (wait 18 [3 4 3 1 2]))
{0 3,
7 1,
1 5,
4 2,
6 5,
3 2,
2 3,
5 1,
8 4}
day6> (reduce + (vals (frequencies (wait 18 [3 4 3 1 2]))))
26
So this shows that we can simply maintain such a table ourselves without adding fish to the end of the list, as original rules suggest. Let’s write such function:
day6> (defn solve [days input]
(reduce (fn [generation _]
(reduce (fn [new-gen [tick conut]] ; ❸
(if (> tick 0)
(update new-gen (dec tick) (fnil + 0) conut) ; ❹
(-> new-gen
(update 6 (fnil + 0) conut)
(update 8 (fnil + 0) conut)))) ; ❺
{} generation)) ; ❷
(frequencies input) ; ❶
(range days)))
#'day6/solve
day6> (solve 18 [3 4 3 1 2])
{0 3, 7 1, 1 5, 4 2, 6 5, 3 2, 2 3, 5 1, 8 4}
There’s a lot that’s going on, so let me explain it.
First, we compute the initial counts of each fish ❶.
Then we reduce into this generation over the number of days we need to wait computed with (range days).
The reducing function accepts a generation and a day, but we only need the generation itself.
Then we reduce over this generation into a new empty one ❷.
The inner reducing function accepts new-gen - a new generation to compute, and a fish, immediately destructured to tick and fish count ❸.
If the tick is greater than zero, this fish goes into new generation with the tick value decreased by 1.
Otherwise, we add another fish with the counter of 6 to the new generation, and a new fish with the counter of 8 ❺.
On each iteration of the inner reduce we update fish similarly to our tick and populate functions, but without generating longer list.
And as you can see, calling this function returns the same result as our previous implementation, but the time needed is significantly lower:
day6> (= (frequencies (wait 80 [3 4 3 1 2]))
(solve 80 [3 4 3 1 2]))
true
day6> (do (time (wait 80 [3 4 3 1 2]))
(time (solve 80 [3 4 3 1 2]))
nil)
"Elapsed time: 43.779213 msecs"
"Elapsed time: 0.585191 msecs"
nil
Computing 256 days finishes in an instant, even with the real input:
day6> (reduce + (vals (solve 256 [3 4 3 1 2])))
26984457539
day6> (reduce + (vals (solve 256 (read-input))))
1675781200288
And this gives us the second gold star.
Day 6 thoughts
This was an interesting task! It shows that the most obvious approach is not always the most optimal one, and I’ve intentionally solved it in a nonoptimal way to show that. And using this solution helped us to see how to do it the proper way.
Day 7 - The Treachery of Whales
Remembering last year’s AoC, I can tell that solving one puzzle per day is much more pleasant than solving a bunch of puzzles in a single day. Last year I felt the burden of unsolved days, and an eternal race with the clock to keep up with others. Thankfully, this year is different!
Today a giant whale wants to eat us, but a swarm of crabs in tiny submarines wants to help us escape.
In order to do that, we need to help crabs to align in a straight line with the least amount of fuel.
The example input resembles a horizontal position of each crab, and goes as follows: 16,1,2,0,4,2,7,1,2,14.
When crab moves from position 0 to position 1 its submarine looses 1 unit of fuel.
So to move from position 16 to 5, the crab needs to spend 11 units of fuel.
We need to find such a position that total fuel unit loss is as small as possible.
Let’s start with the example input:
day6> (ns day7)
nil
day7> (require '[aoc-commons :refer [parse-long]]
'[clojure.string :as str])
nil
day7> (def example-input [16,1,2,0,4,2,7,1,2,14])
#'day7/example-input
Now we just need to compute fuel consumption for a given position:
day7> (defn fuel-consumption [input pos]
(->> input
(map #(Math/abs (- % pos)))
(reduce +)))
#'day7/fuel-consumption
day7> (fuel-consumption example-input 2)
37
As can be seen, computing fuel consumption for position 2 yields a correct result.
Now we only need to check what position is the most optimal one, meaning that it uses the least amount of fuel:
day7> (defn solve [input]
(let [min (apply min input)
max (apply max input)]
(->> (range min (inc max))
(map (partial fuel-consumption input))
sort
first)))
#'day7/solve
day7> (solve example-input)
37
We only care for the positions in range of our numbers.
So if the minimum position is 10 and the maximum is 15 there’s no point going below 10 or above 15.
Since the range yields a non-inclusive range, we need to inc the upper bound.
This again yields 37, as it is the least amount of fuel we can use to align everyone.
It also works for the real input, but it is quite slow:
day7> (time (solve (read-input)))
"Elapsed time: 6545.965142 msecs"
343468
While slowness may be an issue in the second part, as the previous day clearly illustrated, let’s hope it will not cause too much trouble.
Part two
OK, we’ve got it slightly wrong, and crab submarines use a lot more fuel to move.
So to move from position 1 to 5, the submarine uses 1+2+3+4+5 amount of fuel.
This is called a triangular number, and is computed with the following formula: n(n+1)/2:
day7> (defn triangle-number [n]
(/ (* n (inc n)) 2))
#'day7/triangle-number
day7> (triangle-number 5)
15
Now, all we need to do is to plug this function into our solution.
Instead of duplicating the code, let’s rewrite our two functions to support an additional modifier argument:
day7> (defn fuel-consumption [input modifier pos]
(->> input
(map #(modifier (Math/abs (- % pos))))
(reduce +)))
#'day7/fuel-consumption
day7> (defn solve
([input] (solve input identity))
([input modifier]
(let [min (apply min input)
max (apply max input)]
(->> (range min max)
(map (partial fuel-consumption input modifier))
sort
first))))
#'day7/solve
The solve function now optionally accepts a second argument.
When only one argument is given, the arity dispatcher goes to the first body ([input] (solve input identity)), which calls the same function but with two arguments.
The default value for modifier is identity, which is a function that returns the argument it was given as is.
Now we can use our triangle-number as a modifier to compute the result:
day7> (solve example-input)
37
day7> (solve example-input triangle-number)
168
This works for real input data as well:
day7> (time (solve (read-input) triangle-number))
"Elapsed time: 6256.100167 msecs"
96086265
The required time hasn’t changed much, as we just added one small formula to an already working solution. I’m fine with the current results.
Day 7 thoughts
Today’s task was quite simple. Perhaps there’s a more optimal solution to it, but I can’t think of one to be honest. Luckily, today the speed was not a blocker, just a minor inconvenience.
Day 8 - Seven Segment Search
After escaping from the giant whale we’ve entered a cave and noticed that our submarine’s four-digit seven-segment display is malfunctioning. The digits on the display are meant to look like this:
0: 1: 2: 3: 4:
aaaa .... aaaa aaaa ....
b c . c . c . c b c
b c . c . c . c b c
.... .... dddd dddd dddd
e f . f e . . f . f
e f . f e . . f . f
gggg .... gggg gggg ....
5: 6: 7: 8: 9:
aaaa aaaa aaaa aaaa aaaa
b . b . . c b c b c
b . b . . c b c b c
dddd dddd .... dddd dddd
. f e f . f e f . f
. f e f . f e f . f
gggg gggg .... gggg gggg
However, random gibberish is displayed, due to the fact that the signals are generated randomly. Our test input consists of rows that are divided into two segments - the signals and the numbers:
acedgfb cdfbe gcdfa fbcad dab cefabd cdfgeb eafb cagedb ab | cdfeb fcadb cdfeb cdbaf
Everything before the | character are the patterns produced by our system, and everything after is the number meant to be displayed.
The task goes into great detail on how this works, but the first part doesn’t use anything of it so let’s just skip it for now. Our task for the first part is to find all unique numbers, which can be determined by lengths, and find how many they’re appearing. Let’s start by parsing the example input first:
day7> (ns day8)
nil
day8> (require '[aoc-commons :refer [parse-long]]
'[clojure.string :as str])
nil
day8> (def example-input
"be cfbegad cbdgef fgaecd cgeb fdcge agebfd fecdb fabcd edb | fdgacbe cefdb cefbgd gcbe ...")
#'day8/example-input
day8> (defn read-input []
(->> #_#_"inputs/day8"
slurp
example-input
str/split-lines
(map (fn [line]
(let [[signals digits] (str/split line #"\s+\|\s+")]
{:signals (str/split signals #"\s+")
:digits (str/split digits #"\s+")})))))
#'day8/read-input
This transforms each row into a hashmap that holds :signals and :digits keys:
day8> (read-input)
({:signals ["be" "cfbegad" "cbdgef" "fgaecd" "cgeb"
"fdcge" "agebfd" "fecdb" "fabcd" "edb"],
:digits ["fdgacbe" "cefdb" "cefbgd" "gcbe"]}
...)
Our task is to find only the digits that have a unique size, meaning only 1, 4, 7, and 8, with the respective sizes of 2, 3, 4, and 7:
day8> (defn part-1 [input]
(->> input
(map :digits)
(mapcat #(map count %))
(keep #{2 3 4 7})
count))
#'day8/part-1
day8> (part-1 (read-input))
381
Nothing fancy here, just counting all digit code lengths and keeping only those that match the predicate. Now for the real thing.
Part two
I’ve thought I went insane. The second part starts off with the brief explanation that after a short period of time we’ve figured out how the signals are wired:
acedgfb cdfbe gcdfa fbcad dab cefabd cdfgeb eafb cagedb ab | cdfeb fcadb cdfeb cdbaf
The signals can be wired as follows:
dddd aaaa
e a b c
e a b c
ffff dddd
g b e f
g b e f
cccc gggg
our correct
mapping mapping
Which means that the patterns for all numbers are:
| Signal | Digit |
|---|---|
acedgfb |
8 |
cdfbe |
5 |
gcdfa |
2 |
fbcad |
3 |
dab |
7 |
cefabd |
9 |
cdfgeb |
6 |
eafb |
4 |
cagedb |
0 |
ab |
1 |
And now I feel very stupid, but at first, I’ve thought that this is the thing I need to use to complete the task. I wrote a small function that uses these patterns as a decoder and run it over the example input and got the wrong answer.
I know, it may sound ridiculous but I’ve spent 20 minutes trying to figure out why the second line has the one digit represented as gc and the fourths one uses cb.
Only after I’ve realized that my task is to compute such patterns for all rows, and there’s no universal one.
Well, I guess I was misled by this sentence:
Following this same process for each entry in the second, larger example above, the output value of each entry can be determined:
I’ve understood it as if I don’t need to figure out the wiring first. But now that the task is clear to me let’s try to think of how it can be accomplished.
First things first, we know four digits from the get go: 1, 4, 7, and 8, so we can compute their patterns easily enough:
- one:
c,f - four:
b,c,d,f - seven:
a,c,f - eight:
a,b,c,d,e,f
And we need to find the remaining numbers using only this information. Except no. Remember the diagram at the start of the puzzle? We can use it to find which letters we can compute by overlaying digits one on another and removing those that we’re not interested in. This basically means, we need to use mathematical sets to solve this task. Luckily for us, Clojure comes with a built in set library:
day8> (require '[clojure.set :as set])
nil
day8> (def signals (map set ["acedgfb" "cdfbe" "gcdfa" "fbcad" "dab" "cefabd" "cdfgeb" "eafb" "cagedb" "ab"]))
#'day8/signals
Now we can start by finding the patterns. First, let’s determine the patterns for the known digits:
day8> (def one one (some #({2 %} (count %)) signals))
#'day8/one
day8> (def four (some #({4 %} (count %)) signals))
#'day8/four
day8> (def seven (some #({3 %} (count %)) signals))
#'day8/seven
day8> (def eight (some #({7 %} (count %)) signals))
#'day8/eight
The first thing we can do is find what letter a is mapped to.
To do so, we can take the difference between seven and one, as this will leave only the topmost row:
7777
. 1
. 1
....
. 1
. 1
....
day8> (def a (first (set/difference seven one)))
#'day8/a
day8> a
\d
As can be seen, for the given signals the topmost row is mapped to the character d.
With the digits we know so far we can find another character g:
day8> (def g (some #(when-let [c (and (= 6 (count %))
(set/difference % (set/union seven four)))]
(when (= 1 (count c))
(first c)))
signals))
#'day8/g
day8> g
\c
We’re using the fact that there’s only one digit with the length of 6, that has exactly one extra line from the union of seven and four, which looks like an unfinished nine:
7777 9999
4 7 9 9
4 7 9 9
4444 9999
. 7 . 9
. 7 . 9
.... 9999
And the bottom line corresponds to the g letter in the correct mapping.
We now can actually define nine by using union of seven, four, and newly found g:
day8> (def nine (set/union #{g} seven four))
#'day8/nine
day8> nine
#{\a \b \c \d \e \f}
And with nine available, we can find e by taking a difference with eight:
....
. .
. .
....
8 .
8 .
....
day8> (def e (first (set/difference eight nine)))
#'day8/e
day8> e
\g
There’s another number we can find by only knowing 8 and 1, it is six.
We can do this similarly to how we’ve found letter g, except now we’re finding whole number instead:
day8> (def six (some #(and (= (count %) 6)
(seq (set/intersection
one
(set/difference eight (set %))))
%)
signals))
#'day8/six
day8> six
#{\b \c \d \e \f \g}
This works because there’s only one number that has 6 segments, and when we difference it with eight the remaining segment will intersect with 1:
....
. 6
. 6
....
. 1
. 1
....
That’s how we know that this is truly six.
And with six in place, we are able to find letters c and f:
day8> (def c (first (set/difference eight six)))
#'day8/c
day8> c
\a
day8> (def f (first (disj one c)))
#'day8/f
day8> f
\b
I hope you get why this is like this, as I’m a bit tired to draw these numbers, haha…
Speaking of number, now, that we know both six and letter c, we can compute five, by removing c from six:
day8> (def five (disj six e))
#'day8/five
day8> five
#{\b \c \d \e \f}
And five is the key point of finding two:
day8> (def two (some #(and (= (count %) 5)
(= #{c e}
(set/difference
%
five))
%)
signals))
#'day8/two
day8> two
#{\a \c \d \f \g}
Knowing two grants us access to three by merging two with f and removing e.
And while we’re there, we can actually find letter d from two as well:
day8> (def three (conj (disj two e) f))
#'day8/three
day8> three
#{\a \b \c \d \f}
day8> (def d (first (disj two a c e g)))
#'day8/d
day8> d
\f
Finally, we went through all this trouble to find the last digit:
day8> (def zero (disj eight d))
#'day8/zero
day8> zero
#{\a \b \c \d \e \g}
Now, if you remember, we have the example mapping:
| Signal | Digit |
|---|---|
acedgfb |
8 |
cdfbe |
5 |
gcdfa |
2 |
fbcad |
3 |
dab |
7 |
cefabd |
9 |
cdfgeb |
6 |
eafb |
4 |
cagedb |
0 |
ab |
1 |
Let’s compare it to ours:
day8> {zero 0, one 1, two 2, three 3, four 4, five 5, six 6, seven 7, eight 8, nine 9}
{#{\a \c \e \d \g \f \b} 8,
#{\c \d \f \b \e} 5,
#{\g \c \d \f \a} 2,
#{\f \b \c \a \d} 3,
#{\d \a \b} 7,
#{\c \e \f \a \b \d} 9,
#{\c \d \f \g \e \b} 6,
#{\e \a \f \b} 4,
#{\c \a \g \e \d \b} 0,
#{\a \b} 1}
As you can see it’s exactly the same3.
All that is left to do is to put all this logic into a function and use this function to decode the numbers.
I won’t repeat the whole code from above again, as this post is already a bit long, so the function I wrote is called map-signals-to-digits, and here’s the solution:
day8> (defn decode [row]
(let [{:keys [signals digits]} row
signals->digits (map-signals-to-digits signals)]
(->> digits
(map set)
(map signals->digits)
(str/join)
parse-long)))
#'day8/decode
day8> (defn part-2 [input]
(->> input
(map decode)
(reduce + )))
#'day8/part-2
day8> (part-2 (read-input))
1023686
Day 8 thoughts
This task was really tricky. I’ve spent a lot of time mapping numbers by hand before I’ve managed to find a sequence of letters/digits that works to find all of them. The solution is a bit too imperative for my liking, but hey, it works, and I’m already exhausted enough, so I can take it in its current state.
Technically speaking, I’ve finished this task after midnight at my local time, but there still was time until the next task, so I think this counts, as a win.
Day 9 - Smoke Basin
The caves we’ve entered seem to be the lava tubes. Ans some of the tubes are still active. Our puzzle input is the heightmap of the tubes, which looks like this:
2199943210
3987894921
9856789892
8767896789
9899965678
The bold numbers are the low points - the locations that are lower than any of its adjacent locations.
It means that these points are the smallest in the surrounding area (excluding diagonals).
This example has four low points, which are 1, 0, 5, and 5.
Our task is to compute the risk level, which is computed by the height of the point plus 1.
In this case risk levels are 2, 1, 6, and 6.
Adding those together produces the total risk level of 15.
Let’s start by parsing the input:
day8> (ns day9)
nil
day9> (require '[aoc-commons :refer [parse-long]]
'[clojure.string :as str])
nil
day9> (def example-input "
2199943210
3987894921
9856789892
8767896789
9899965678")
#'day9/example-input
day9> (defn read-input []
(->> example-input
str/trim
str/split-lines
(mapv #(mapv (fn [s] (parse-long (str s))) %))))
#'day9/read-input
day9> (read-input)
[[2 1 9 9 9 4 3 2 1 0]
[3 9 8 7 8 9 4 9 2 1]
[9 8 5 6 7 8 9 8 9 2]
[8 7 6 7 8 9 6 7 8 9]
[9 8 9 9 9 6 5 6 7 8]]
Sweet! Now we need to find the points that represent the lowest values and their surroundings. Let’s write a function that checks if the point in the row is the smallest from the ones near it. We’re not going to check other rows just yet:
day9> (defn find-minimum [row]
(->> row
(map-indexed #(and (< %2 (nth row (dec %1) 9))
(< %2 (nth row (inc %1) 9))
%1))
(filter number?)
(into [])))
#'day9/find-minimum
day9> (find-minimum (first (read-input)))
[1 9]
This function walks the row via the map-indexed function, which accepts the index of an element as the first argument and the element itself as the second one.
We’re abusing the fact that the largest number in the input is 9, and if we go out of bounds we simply use 9 as a fallback.
The return value is a vector of indexes that matches our criteria.
But this is only the info about a single dimension, e.g. a column, we need to populate it with the row number as well:
day9> (defn find-row-min-points [rows]
(->> rows
(mapv find-minimum)
(map-indexed #(mapv (fn [e] [%1 e]) %2))
(into [])))
#'day9/find-row-min-points
day9> (find-row-min-points (read-input))
[[[0 1] [0 9]]
[[1 0] [1 3] [1 6] [1 9]]
[[2 2] [2 7] [2 9]]
[[3 2] [3 6]]
[[4 1] [4 6]]]
Oh, this looks like a mess, but it is correct, trust me.
But, you know, you don’t have to trust me!
Instead, let’s write a render function, similarly to how we did in solution for the day 5:
day9> (defn render [rows coordinates]
(let [x (count rows)
y (count (first rows))
field (into [] (repeat x (into [] (repeat y "."))))]
(->> coordinates
(reduce (fn [field p]
(assoc-in field p (get-in rows p))) field)
(map str/join)
(map (partial str ";; "))
(str/join "\n")
println)))
#'day9/render
We can’t render things just yet, as this function accepts a flat list of coordinates, like this one: [[0 1] [1 0] [0 0].
Our current coordinate list is not flat, as it contains rows, but since we’ve incorporated the row number into the stored points, we can flatten this structure like this:
day9> (defn to-single-level [rows]
(reduce (fn [all row] (concat all row)) [] rows))
#'day9/to-single-level
day9> (to-single-level (find-row-min-points (read-input)))
([0 1]
[0 9]
[1 0]
[1 3]
[1 6]
[1 9]
[2 2]
[2 7]
[2 9]
[3 2]
[3 6]
[4 1]
[4 6])
day9> (render (read-input) (to-single-level (find-row-min-points (read-input))))
;; .1.......0
;; 3..7..4..1
;; ..5....8.2
;; ..6...6...
;; .8....5...
nil
Right now this doesn’t look like the expected result, but this is because we’re only using horizontal information, so there are some points that we need to filter out.
To do so, let’s transpose our rows, so rows would become columns and repeat the algorithm:
day9> (defn transpose [m]
(apply mapv vector m))
#'day9/transpose
day9> (let [rows (transpose (read-input))]
(render rows (to-single-level (find-row-min-points rows))))
;; 2..8.
;; 1..7.
;; ..5..
;; ..6..
;; ..7..
;; 4.8.6
;; 3...5
;; 2...6
;; 1...7
;; 0...8
nil
Now we just need to combine the two sets of coordinates, and we’ll get our points:
day9> (require '[clojure.set :as set])
nil
day9> (defn lowest-points [rows]
(let [min-rows (->> rows
find-row-min-points
to-single-level
set)
min-cols (->> rows
transpose
find-row-min-points
to-single-level
(map (fn [[x y]] [y x]))
set)]
(into [] (set/intersection min-rows min-cols))))
#'day9/lowest-points
day9> (render (read-input) (lowest-points (read-input)))
;; .1.......0
;; ..........
;; ..5.......
;; ..........
;; ......5...
nil
Bingo! Oh, wait, the wrong day. Looks around, hoping that there is no giant squid nearby.
Ahem, we got our points and these are the exact points from the example high above. All that’s left is to get their values out, increment and sum:
day9> (defn part-1 [input]
(->> input
lowest-points
(map #(get-in input %))
(map inc)
(reduce +)))
#'day9/part-1
day9> (part-1 (read-input))
15
This grants us the first gold star! Let’s see what we need to do next.
Part two
And next, we need to find the largest basins so we would know what areas are most important to avoid.
A basin is represented by a location where the numbers flow downward to the minimum one.
9 is not the part of the basin, so we need to exclude it from the data.
Here’s one of the basins in the example input data:
2199943210
3987894921
9856789892
8767896789
9899965678
You can see that it is surrounded by number 9.
The size of the basin is determined by the number of numbers in it, this particular basin has a size of 14.
We need to find the three largest basins in our input data and multiply their sizes.
Let’s start by writing a rule that will check if the point is a part of the basin:
day9> (defn part-of-basin? [val lowest]
(<= lowest val 8))
#'day9/part-of-basin?
This simply checks that the value is higher or equal to the lowest one in the basin, and is smaller than 9.
Now we need to find all coordinates that belong to a basin for a given point:
day9> (defn find-basin [coords rows [x y] val]
(when (part-of-basin? (get-in rows [x y] 10) val)
(vswap! coords conj [x y])
(doseq [coord [[(inc x) y]
[(dec x) y]
[x (inc y)]
[x (dec y)]]]
(find-basin coords rows coord (inc val)))))
#'day9/find-basin
Aah, watch out! A wild non-pure recursive function appeared!
Did I scare you? Don’t worry, this function is the simplest solution I could though of for finding all points that belong to a basin. Yes, it’s a shame that it is mutable, but I didn’t want to bother writing it in such a way that it would pass its state to subsequent calls, so bear with me. I’ll explain what it does in just a bit, but right now let me show you that it can find the example basin:
day9> (let [rows (read-input)
basin (volatile! #{})]
(find-basin basin rows [2 2] 5)
(render rows @basin))
;; ..........
;; ..878.....
;; .85678....
;; 87678.....
;; .8........
nil
As you can see it found the correct basin for the point with the coordinates of [2 2] and a value of 5.
So how does it do that?
The first thing we do in this function checks whether the point is a part of the basin, meaning that it is between the lowest point and 9.
Since our first point is the lowest one already this function returns true, we add it to the coords and go into the doseq.
It then loops through a new set of points, directly above, below, to the right, and to the left of the current one, and goes into the next recursion step, incrementing the minimum value.
This way we can check all points up until the only points left are 9 ones, and we exit this function.
And since coords is expected to be a set, there will be no duplicates, even though we visit the same points over and over again.
Now, when we can find a single basin, all that is left is to find all of them:
day9> (defn find-basins [rows]
(let [points (lowest-points rows)]
(for [p points]
(let [coords (volatile! #{})]
(find-basin coords rows p (get-in rows p))
@coords))))
#'day9/find-basins
day9> (render (read-input) (to-single-level (find-basins (read-input))))
;; 21...43210
;; 3.878.4.21
;; .85678.8.2
;; 87678.678.
;; .8...65678
nil
Here are all basins on the same coordinate field.
You can see that they’re separated by . symbols, meaning that there were 9.
Finally, we need to count all their sizes, sort, take the first three and multiply:
day9> (defn part-2 [input]
(->> input
find-basins
(map count)
(sort >)
(take 3)
(reduce *)))
#'day9/part-2
day9> (part-2 (read-input))
1134
This grants us the second gold star!
Day 9 thoughts
It may seem that this task was easy, but that’s the beauty of blogging - you never know how hard it was to me in reality. Honestly, it wasn’t as straightforward as I’ve described here, as I was uncertain how to find basins correctly. For example, there’s the following line:
Locations of height 9 do not count as being in any basin, and all other locations will always be part of exactly one basin.
I’ve assumed that there might be some basins that are connected, and thus share some lowest points, but no. However, by doing this check I got the wrong answer and was unsure why. Until I’ve accidentally removed this check and got the right one. Interestingly enough, with or without this check the code worked perfectly with the example input. So yeah…
Day 10 - Syntax Scoring
After we’ve determined which basins to avoid we ask our submarine to find a safe route, but it reports that there’s an error:
Syntax error in navigation subsystem on line: all of them
And here’s our navigation subsystem that we need to fix:
[({(<(())[]>[[{[]{<()<>>
[(()[<>])]({[<{<<[]>>(
{([(<{}[<>[]}>{[]{[(<()>
(((({<>}<{<{<>}{[]{[]{}
[[<[([]))<([[{}[[()]]]
[{[{({}]{}}([{[{{{}}([]
{<[[]]>}<{[{[{[]{()[[[]
[<(<(<(<{}))><([]([]()
<{([([[(<>()){}]>(<<{{
<{([{{}}[<[[[<>{}]]]>[]]
So all lines are incorrect but for two different reasons. Some lines are just unfinished, e.g. all parentheses and brackets are stacked logically, there’s just not enough closing characters to match them. Other lines are indeed incorrect, because the closing paren doesn’t match the opening one, like here:
{([(<{}[<>[]}>{[]{[(<()>We’ve expected a matching ] but instead found the }, which is not right.
The puzzle claims that all syntax checkers have a scoring system, and in our case, the scores are like this:
): 3 points,]: 57 points,}: 1197 points,>: 25137 points.
Our task is to find all non-matching parentheses in the input, and compute the total score.
day9> (ns day10)
nil
day10> (require '[clojure.string :as str])
nil
day10> (def example-input "
[({(<(())[]>[[{[]{<()<>>
[(()[<>])]({[<{<<[]>>(
{([(<{}[<>[]}>{[]{[(<()>
(((({<>}<{<{<>}{[]{[]{}
[[<[([]))<([[{}[[()]]]
[{[{({}]{}}([{[{{{}}([]
{<[[]]>}<{[{[{[]{()[[[]
[<(<(<(<{}))><([]([]()
<{([([[(<>()){}]>(<<{{
<{([{{}}[<[[[<>{}]]]>[]]")
#'day10/example-input
day10> (def incorrect-score
{\) 3
\] 57
\} 1197
\> 25137})
#'day10/incorrect-score
day10> (defn read-input []
(->> example-input
str/trim
str/split-lines))
I’ve defined the score map as described in the task, but I’m using characters instead of strings, as it’s easier to work with them because strings in Clojure can be represented as sequences of characters. Now, we need a way to find what character is not the matching one.
The solution is pretty simple - a stack. We add opening characters to the stack, and when we get a closing one, we check if there’s a matching parenthesis is on the top of the stack. If it matches, we remove it from the stack and continue. If it doesn’t match, we’ve found the culprit.
day10> (def matching
{\( \),
\{ \},
\[ \],
\< \>})
#'day10/matching
day10> (defn to-stack-or-error-char [line]
(loop [stack ()
[paren & parens] line]
(case paren
(\( \[ \{ \<) (recur (cons paren stack) parens)
(\) \] \} \>) (if (= (matching (first stack)) paren)
(recur (rest stack) parens)
paren)
stack)))
#'day10/to-stack-or-error-char
This function builds the stack and if there were no mismatching chars it returns it, otherwise, it returns the mismatched character.
I’ve also created the matching table, to quickly convert opening parens into the matching closing ones.
Here’s how it works:
day10> (to-stack-or-error-char "[({(<(())[]>[[{[]{<()<>>")
(\{ \{ \[ \[ \( \{ \( \[)
day10> (to-stack-or-error-char "{([(<{}[<>[]}>{[]{[(<()>")
\}
Pretty universal, but maybe a bit inconvenient to use. Now, all that’s left is to find mismatches for all lines, and calculate the score:
day10> (defn part-1 [input]
(->> input
(keep to-stack-or-error-char)
(filter char?)
(map incorrect-score)
(reduce +)))
#'day10/part-1
day10> (part-1 (read-input))
26397
I’m filtering results, only keeping those that are single characters as the (keep to-stack-or-error-char input) call returns a list of both stacks and chars.
Part two
This solves only half of our problems. We still have a lot of lines that are valid, but unfinished, and our second task is to finish those and compute a completion score:
The completing score is a bit different from the mismatch score:
day10> (def correct-score
{\) 1
\] 2
\} 3
\> 4})
#'day10/correct-score
To calculate the score, we need to fill the stack first.
Except not, we can just use the valid stack and swap all opening parentheses to the closing ones.
Then we can score those and calculate the total score.
Total score is calculated by this formula (score-so-far * 5) + paren-score for each parenthesis.
Sounds like a job for reduce:
day10> (defn score-completion-stack [stack]
(->> stack
(map matching)
(map correct-score)
(reduce (fn [total score]
(+ (* total 5) score)))))
#'day10/score-completion-stack
day10> (score-completion-stack (to-stack-or-error-char "(((({<>}<{<{<>}{[]{[]{}"))
1480781
In the example above I’m passing the correct line, but this function will fail on incorrect inputs. Thankfully we can filter these out by simply checking that elements are collections, similarly to our check in the first part. One last bit we need to make is that to get the correct result we must sort the scores and take exactly the middle one:
day10> (defn get-middle [list]
(first (drop (quot (count list) 2) list)))
#'day10/get-middle
day10> (defn part-2 [input]
(->> input
(map to-stack-or-error-char)
(filter coll?)
(map score-completion-stack)
sort
get-middle))
#'day10/part-2
day10> (part-2 (read-input))
288957
Clojure doesn’t have a function to get the middle element of the collection directly, but it’s quite easy to do, so it’s not a problem.
And the quot function helps avoiding direct use of java.lang.Math/floor or casting fractions to int with int.
Day 10 thoughts
This day’s task was easy.
I think this was mostly due to the fact that I’ve already written a Scheme-like language before, where I solved exactly the same problem.
Except there I’ve used a bit simpler solution as I’ve only needed to check the last character, as was not planning to automatically complete the stack.
InterLisp mapped the ] key to a shortcut that closed all opened parentheses before the cursor.
I think this could be possible to be done in the Reader, though it would annoy a lot of text editors as they expect parentheses to be balanced.
Today’s puzzle was fun, and I think it’s even practical as it teaches you how to parse structured data with a stack.
Day 11 - Dumbo Octopus
After figuring out the deadliest basins, we enter another cave full of dumbo octopuses, officially named as Grimpoteuthis.
There are 100 octopuses arranged in a 10 by 10 grid, and each one has an energy level from 0 to 9.
Each discrete moment, every octopus gets one additional power to their power level, and after an octopus got more than 9 power, it flashes red.
Flashing makes all neighbor octopuses obtain one extra energy unit, with a catch that an octopus that already flashed will not flash twice in a single step.
After flashing, the energy level of that octopus is reset to 0.
So it goes like this. Suppose we have these octopuses:
1 1 1 1 1
1 9 9 9 1
1 9 1 9 1
1 9 9 9 1
1 1 1 1 1
After the first step, all inner one flashed and increased the surrounding levels by 1.
This makes the innermost octopus to also flash:
3 4 5 4 3
4 0 0 0 4
5 0 0 0 5
4 0 0 0 4
3 4 5 4 3
After the next step, no octopus needs to flash, so their levels just increase:
4 5 6 5 4
5 1 1 1 5
6 1 1 1 6
5 1 1 1 5
4 5 6 5 4
This is how the task puts it. Let’s see if we can implement such an algorithm. This actually looks like a cellular automaton, except neighbor cells just change their levels upon flashing. Let’s start by parsing the input, as usual:
day10> (ns day11)
nil
day11> (require '[aoc-commons :refer [parse-long]]
'[clojure.string :as str])
nil
day11> (def example-input "
11111
19991
19191
19991
11111")
#'day11/example-input
day11> (defn read-input []
(->> example-input
str/trim
str/split-lines
(mapv (partial mapv parse-long))))
#'day11/read-input
day11> (read-input)
[[1 1 1 1 1] [1 9 9 9 1] [1 9 1 9 1] [1 9 9 9 1] [1 1 1 1 1]]
Note that I’ve changed the parse-long function to work with not only strings but characters as well.
Now we can define a simple tick function, that will take our world state, and return a new one, where each octopus has increased their level:
day11> (defn tick [rows]
(mapv (partial mapv inc) rows))
#'day11/tick
day11> (tick (read-input))
[[2 2 2 2 2] [2 10 10 10 2] [2 10 2 10 2] [2 10 10 10 2] [2 2 2 2 2]]
As can be seen, this yields us a new world, where some octopuses are basically ready to flash. So let’s write a function that finds all cells that need to flash, and returns their coordinates, similarly to how we did in day 9:
day11> (defn find-flashing-cells [rows]
(->> rows
(keep-indexed
(fn [i row]
(keep-indexed
(fn [j oct]
(when (> oct 9)
[i j]))
row)))
flatten
(partition 2)
(keep seq)))
#'day11/find-flashing-cells
day11> (find-flashing-cells (tick (read-input)))
((1 1) (1 2) (1 3) (2 1) (2 3) (3 1) (3 2) (3 3))
I’ve realized, that since coordinates go in pairs, it’s much easier to bring them to the single level by using flatten and partition, than writing something like day nine’s to-single-level.
Now we just need to update each cell in our world that flashes, and also their neighbors.
Let’s start with a function that will update the cell if it belongs to our world:
day11> (defn safe-update [rows point f]
(if (get-in rows point)
(update-in rows point f)
rows))
#'day11/safe-update
day11> (safe-update [0 1 2] [10] inc)
[0 1 2]
day11> (safe-update [0 1 2] [1] inc)
[0 2 2]
Here, for a one-dimensional example, we first try to update a cell at position 10, but it is out of bounds, so nothing happens.
Next, we successfully update the cell at position 1.
This will work as good for a two-dimensional world we’re dealing with.
Yes, this function will not work in its current state with worlds that have false or nil in any of the cells, but our world doesn’t, so it’s not a problem.
Just something we need to keep in mind.
Now we can flash all cells:
day11> (defn flash
([rows] (flash rows #{}))
([rows flashed]
(reduce (fn [[rows flashed] [x y]]
(if (not (flashed [x y]))
[(-> rows
(safe-update [(inc x) y] inc)
(safe-update [(dec x) y] inc)
(safe-update [x (inc y)] inc)
(safe-update [x (dec y)] inc)
(safe-update [(inc x) (inc y)] inc)
(safe-update [(dec x) (inc y)] inc)
(safe-update [(inc x) (dec y)] inc)
(safe-update [(dec x) (dec y)] inc))
(conj flashed [x y])]
[rows flashed]))
[rows flashed] (find-flashing-cells rows))))
#'day11/flash
Now, this function is pretty big, but its promise is very simple - find all points that need to flash and update all neighbors. Note, that we’re incrementing all neighbor cells, unless the cell already flashed before, which is done by storing all flashed cells into a set. This function then returns a new world’s state, among all cells that have flashed in this step. However, this function doesn’t turn any cells to zero, as it helps with calculation a bit, and we’ll do it later with the following function:
day11> (defn to-zero [rows]
(reduce (fn [rows [x y]] (assoc-in rows [x y] 0))
rows (find-flashing-cells rows)))
#'day11/to-zero
Finally, we need to define the step function, that combines all these and produces a new world state:
day11> (defn step [rows]
(loop [rows rows
[rows* flashed] (flash (tick rows))]
(if (not= rows rows*)
(recur rows* (flash rows* flashed))
[(to-zero rows*)
(count (filter #(> % 9) (flatten rows*)))])))
#'day11/step
Since our task is to count how many octopuses have flashed, we count the set of flashed cells and accumulate it into our result.
So this works like that. We start with the world like the one from the example:
1 1 1 1 1
1 9 9 9 1
1 9 1 9 1
1 9 9 9 1
1 1 1 1 1
First we tick each cell, and world is now in the following state:
2 2 2 2 2
2 10 10 10 2
2 10 2 10 2
2 10 10 10 2
2 2 2 2 2
Now each octopus with the energy level greater than 9 flashes, adding 1 to the energy level of each neighbor:
3 4 5 4 3
4 12 14 12 4
5 14 10 14 5
4 12 14 12 4
3 4 5 4 3
We’ve remembered that on the previous step all octopuses that had 10 already flashed, so on this step only the single one in the very middle needs to flash. And to determine that our world needs another flash, we compare its current state with its previous state:
3 4 5 4 3
4 13 15 13 4
5 15 10 15 5
4 13 15 13 4
3 4 5 4 3
After this step, no other octopus need to flash, so we can replace every power level that is greater than 9 with zero:
3 4 5 4 3
4 0 0 0 4
5 0 0 0 5
4 0 0 0 4
3 4 5 4 3
Now we can repeat this process 100 times, and count how many times there was a flash:
day11> (defn part-1 [input]
(second (reduce (fn [[rows flashed] _]
(let [[rows flashed*] (step rows)]
[rows (+ flashed flashed*)]))
[input 0] (range 100))))
#'day11/part-1
day11> (part-1 (read-input))
1656
And we get a gold star! Time for part two.
Part two
Now our task is to find the step on which all octopuses flash immediately.
Since we already count how many octopuses flashed on each step, all we need is to check if this number equals to 100, as there are one hundred octopuses total:
day11> (defn part-2 [input]
(reduce (fn [[rows flashed] i]
(let [[rows flashed] (step rows)]
(if (= 100 flashed)
(reduced i)
[rows 0])))
[input 0] (rest (range))))
#'day11/part-2
day11> (part-2 (read-input))
195
And we get another gold star by doing that!
Day 11 thoughts
The second part was very easy, as it just requires us to run our simulation until all of the octopuses flashed. Well, the first part wasn’t too hard as well. I remember the previous year’s task Seating System, which was another example of a cellular automaton, and it was a bit harder than this year.
Day 12 - Passage Pathing
The cave story seems to come to an end, as we’re finally heading out of the cave system! However, in order to do that, we need to determine the best path out, and the only way to do that is to find all paths. Our input looks like this:
dc-end
HN-start
start-kj
dc-start
dc-HN
LN-dc
HN-end
kj-sa
kj-HN
kj-dc
Which is a directed graph, that we can visualize like this:
Our task is to find all paths from start to end for this graph, but we can’t go twice through the caves that are marked with lowercase letters.
For the example graph above, all such possible paths are:
start,HN,dc,HN,end
start,HN,dc,HN,kj,HN,end
start,HN,dc,end
start,HN,dc,kj,HN,end
start,HN,end
start,HN,kj,HN,dc,HN,end
start,HN,kj,HN,dc,end
start,HN,kj,HN,end
start,HN,kj,dc,HN,end
start,HN,kj,dc,end
start,dc,HN,end
start,dc,HN,kj,HN,end
start,dc,end
start,dc,kj,HN,end
start,kj,HN,dc,HN,end
start,kj,HN,dc,end
start,kj,HN,end
start,kj,dc,HN,end
start,kj,dc,end
Let’s start by parsing the input:
(ns day12)
nil
day12> (require '[clojure.string :as str])
nil
day12> (def example-input "
start-A
start-b
A-c
A-b
b-d
A-end
b-end")
#'day12/example-input
day12> (defn read-input []
(->> example-input
str/trim
str/split-lines
(map #(str/split % #"-"))
(reduce
(fn [map [start end]]
(-> map
(update start (fnil conj #{}) end)
(update end (fnil conj #{}) start)))
{})))
#'day12/read-input
day12> (read-input)
{"start" #{"b" "A"},
"A" #{"start" "b" "end" "c"},
"b" #{"d" "start" "A" "end"},
"c" #{"A"},
"d" #{"b"},
"end" #{"b" "A"}}
We parse the input into the hashmap, where keys are all caves, and values are the sets of connections. This way we can easily query for the next step we need to make.
Since the task specifically mentions that we need to visit lower-cased caves only once, it would be nice to have a predicate for this kind of check:
day12> (defn lower-case? [s]
(= s (str/lower-case s)))
#'day12/lower-case?
day12> (lower-case? "A")
false
day12> (lower-case? "a")
true
Now we can start building paths. To do so, let’s start with a function, that when given a path, will determine all possible steps, depending on our routes:
day12> (defn all-possible-steps [routes path]
(let [seen (frequencies (filter lower-case? path))]
(filter some? (for [end (routes (last path))]
(when (not (seen end))
(str/join "," (conj path end)))))))
#'day12/all-possible-steps
day12> (all-possible-steps (read-input) ["start"])
("start,b" "start,A")
I’m using strings here because I’ll be using flatten a bit later, so I can’t use vectors here, unfortunately.
This is definitively a hack, but I couldn’t figure out a proper way.
Now we can build all possible paths:
day12> (defn build-paths [routes]
(loop [paths [["start"]]
done []]
(let [paths (->> paths
(map #(all-possible-steps routes %))
flatten
(filter some?)
(map #(str/split % #",")))]
(if (seq paths)
(recur (remove #(= (last %) "end") paths)
(concat done (filter #(= (last %) "end") paths)))
done))))
#'day12/build-paths
This function loops until we exhaust all possible combinations.
Each path that ends with the end cave is moved to a separate list of paths, named done, which is returned upon end.
Here’s an example:
day12> (defn build-paths [routes]
(loop [paths [["start"]]
done []]
(let [paths (->> paths
(map #(all-possible-steps routes %))
flatten
(filter some?)
(map #(str/split % #",")))]
(if (seq paths)
(recur (remove #(= (last %) "end") paths)
(concat done (filter #(= (last %) "end") paths)))
done))))
#'day12/build-paths
day12> (build-paths (read-input))
(["start" "b" "end"]
["start" "A" "end"]
["start" "b" "A" "end"]
["start" "A" "b" "end"]
["start" "A" "b" "A" "end"]
["start" "A" "c" "A" "end"]
["start" "b" "A" "c" "A" "end"]
["start" "A" "c" "A" "b" "end"]
["start" "A" "b" "A" "c" "A" "end"]
["start" "A" "c" "A" "b" "A" "end"])
This method correctly works for all examples and on the real input.
We only need to count the result, and we get the first gold star for this day.
Part two
Part two suggests that we might want to enter a single small cave twice. I’m not sure why would we want this, as we’re searching for the sorest path out of the caves, but, well, OK I guess.
In order to do that, we need to tweak all-possible-steps to check how many lower-cased letters there were.
To do that, we can count each letter, and see if their sum is equal to the amount of letters:
day12> (let [letters ["a" "b" "c" "d"]
counts (frequencies letters)]
(= (count (keys counts)) (reduce + (vals counts))))
true
This would work for the unique case, but we’re allowed to enter a single lower-cased cave twice.
Which just means that we can compare if the amount of counts is greater than amount of letters by 1:
day12> (let [letters ["a" "b" "c" "d" "b" "b"]
counts (frequencies letters)]
(or (= (count (keys counts)) (reduce + (vals counts)))
(= (inc (count (keys counts))) (reduce + (vals counts)))))
false
day12> (let [letters ["a" "b" "c" "d" "b"]
counts (frequencies letters)]
(or (= (count (keys counts)) (reduce + (vals counts)))
(= (inc (count (keys counts))) (reduce + (vals counts)))))
true
Now we just need to add this logic to all-possible-steps:
day12> (defn all-possible-steps-2 [routes path]
(let [seen (frequencies (filter lower-case? path))
vn (reduce + (vals seen))
kn (count (keys seen))]
(when (or (= vn kn)
(= vn (inc kn)))
(->> path
last
routes
(map #(when (not= % "start")
(str/join "," (conj path %))))))))
#'day12/all-possible-steps-2
We’re not interested in paths that lead back to the start, but since we don’t check for visited nodes anymore, we need to accommodate this specific case.
Now we just need to update build-paths to use this function instead of the previous variant.
But instead, let’s pass this function as an argument:
day12> (defn build-paths [routes steps]
(loop [paths [["start"]]
done []]
(let [paths (->> paths
(map #(steps routes %))
flatten
(filter some?)
(map #(str/split % #",")))]
(if (seq paths)
(recur (remove #(= (last %) "end") paths)
(concat done (filter #(= (last %) "end") paths)))
done))))
#'day12/build-paths
The smallest test example produces 36 paths, which is a bit too much for the blog post lengths, so here’s a smaller example:
day12> (build-paths {"start" #{"A" "b"}
"A" #{"start" "b" "end"}
"b" #{"start" "A" "end"}
"end" #{"A" "b"}}
all-possible-steps-2)
(["start" "b" "end"]
["start" "A" "end"]
["start" "b" "A" "end"]
["start" "A" "b" "end"]
["start" "b" "A" "b" "end"]
["start" "A" "b" "A" "end"]
["start" "b" "A" "b" "A" "end"]
["start" "A" "b" "A" "b" "end"]
["start" "A" "b" "A" "b" "A" "end"])
As can be seen, this works exactly how we need, and grants us another gold star when used on the real input data.
Day 12 thoughts
This task was tough. It may not look like it, but I don’t like combination-based tasks too much. It was pretty hard to figure out the optimal strategy to discover all possible paths, and don’t go into infinite loops. But I’ve made it through, and still maintaining the streak!
Day 13 - Transparent Origami
It seems I’ve celebrated early, and the cave story goes on still. Our submarine reached another volcanically active part of the cave! In order to progress, we need to use our onboard thermal camera, which, unfortunately, wasn’t activated ever since it was installed. To activate the camera we need to input a code, which can be found in the manual.
However, the code is protected from copying by being marked on transparent paper with dots. By folding this paper accordingly to the instructions, we will be able to decipher the code.
Our example puzzle input looks like this:
6,10
0,14
9,10
0,3
10,4
4,11
6,0
6,12
4,1
0,13
10,12
3,4
3,0
8,4
1,10
2,14
8,10
9,0
fold along y=7
fold along x=5
Let’s start by parsing it:
day12> (ns day13
(:require [clojure.string :as str]
[aoc-commons :refer [parse-long]]))
nil
day13> (def example-input "
6,10
0,14
9,10
0,3
10,4
4,11
6,0
6,12
4,1
0,13
10,12
3,4
3,0
8,4
1,10
2,14
8,10
9,0
fold along y=7
fold along x=5")
#'day13/example-input
day13> (defn read-input []
(let [lines (->> example-input
str/trim
str/split-lines)
points (take-while seq lines)
folds (rest (drop-while seq lines))]
{:points (mapv #(mapv parse-long (str/split % #",")) points)
:folds (mapv #(update (-> (str/replace % #"fold along\s+" "")
(str/split #"="))
1 parse-long) folds)}))
#'day13/read-input
Today the input parsing function is a bit more involved. We need to not only parse the points but the tasks as well. The resulting data structure simply holds the vector of points and a vector of actions:
day13> (read-input)
{:points
[[6 10] [0 14] [9 10] [0 3]
[10 4] [4 11] [6 0] [6 12]
[4 1] [0 13] [10 12] [3 4]
[3 0] [8 4] [1 10] [2 14]
[8 10] [9 0]],
:folds [["y" 7] ["x" 5]]}
Now, the task shows us that if we render these points to a grid, we’ll get something like this:
...#..#..#.
....#......
...........
#..........
...#....#.#
...........
...........
...........
...........
...........
.#....#.##.
....#......
......#...#
#..........
#.#........
Let’s write a render function, and see if that’s right.
Luckily for us, we’ve already implemented this exact function several times before, in days 9 and 5, so we can reuse it with some small tweaks:
day13> (defn render [points]
(let [x (inc (apply max (map first points)))
y (inc (apply max (map second points)))
field (into [] (repeat x (into [] (repeat y "."))))]
(->> points
(reduce (fn [field p] (assoc-in field p "#")) field)
(apply map vector)
(map str/join)
(map (partial str ";; "))
(str/join "\n")
println)))
#'day13/render
day13> (render (:points (read-input)))
;; ...#..#..#.
;; ....#......
;; ...........
;; #..........
;; ...#....#.#
;; ...........
;; ...........
;; ...........
;; ...........
;; ...........
;; .#....#.##.
;; ....#......
;; ......#...#
;; #..........
;; #.#........
nil
That seems about right! Now, the task suggests that we need to fold this transparent paper once, producing the following transformation:
...#..#..#. #.##..#..#.
....#...... #...#......
........... ......#...#
#.......... => #...#......
...#....#.# .#.#..#.###
........... ...........
........... ...........
--8<---8<--
...........
........... ^
.#....#.##. |
....#...... |
......#...#
#..........
#.#........
So essentially all coordinated below the line are flipped exactly above it. This seems not hard to calculate - we just need to subtract the point’s respecting coordinate from the fold coordinate, only if it is greater than the fold coordinate. Otherwise we return the same coordinate:
day13> (defn fold [point along coord]
(case along
"x" (let [[x y] point]
(if (> x coord)
[(- coord (- x coord)) y]
[x y]))
"y" (let [[x y] point]
(if (> y coord)
[x (- coord (- y coord))]
[x y]))))
#'day13/fold
day13> (render (mapv #(fold % "y" 7) (:points (read-input))))
;; #.##..#..#.
;; #...#......
;; ......#...#
;; #...#......
;; .#.#..#.###
nil
Looks like in the example, so hopefully, we got everything right. The final transformation looks like this:
#.##.|#..#. #####
#...#|..... #...#
.....|#...# #...#
#...#|..... => #...#
.#.#.|#.### #####
.....|..... .....
.....|..... .....
<---
Let’s try folding it this way:
day13> (render (mapv #(fold % "x" 5) (mapv #(fold % "y" 7) (:points (read-input)))))
;; #####
;; #...#
;; #...#
;; #...#
;; #####
nil
Great! This shows that our algorithm behaves at least the same way as the one from the example.
The task for the first part is to only do the first fold, and count amount of unique points. Seems easy:
day13> (count (distinct (mapv #(fold % "y" 7) (:points (read-input)))))
17
For the example input, the correct answer is indeed 17.
Let’s run this against the real input, but actually automate getting the first fold coordinate and axis:
day13> (defn part-1 [input]
(let [{:keys [points folds]} input
[along coord] (first folds)]
(->> points
(mapv #(fold % along coord))
distinct
count)))
#'day13/part-1
day13> (part-1 (read-input))
631
This is the correct answer! Let’s see what’s in the second part.
Part two
We’re asked to finish the rest of the folding, and the code should be represented as eight capital letters.
But wait, there are no letters, in this transparent paper!
I wonder if we’re required to render it?!
day13> (defn part-2 [input]
(let [{:keys [points folds]} input]
(->> folds
(reduce (fn [paper [along coord]]
(mapv #(fold % along coord) paper)) points)
render)))
#'day13/part-2
day13> (part-2 (read-input))
;; ####.####.#....####...##..##..###..####
;; #....#....#....#.......#.#..#.#..#.#...
;; ###..###..#....###.....#.#....#..#.###.
;; #....#....#....#.......#.#.##.###..#...
;; #....#....#....#....#..#.#..#.#.#..#...
;; ####.#....####.#.....##...###.#..#.#...
nil
No way!
Are you kidding me!4
So the code is EFLFJGRF!
Entering the code from above grants us the second gold star for this day. Thankfully, we’re no longer required to figure out how to properly display things on the seven-segment display!
Day 13 thoughts
This task wasn’t hard, but I found it quite fun still! Finally our rendering paid off and proven to be useful.
Funnily enough, I can easily imagine such kind of protection from a device. This was a huge pain in my childhood - my parents often bought games for Dendy a Nintendo Entertainment System clone that was (as everybody thought) the original game console. I’m not sure if this was exactly on Dendy, but I remember that we had black and white displays, and some games required to enter a code to play them, and the code was encrypted via some colorful pallet, and you we’re supposed to enter the code. And some games were bought without manuals, or boxes, which contained the code, thus becoming unplayable. So today’s puzzle brought back some warm memories about my childhood, which is really great! And hey, the half of the event is already over, and I wonder what’s coming next!
Day 14 - Extended Polymerization
Unfortunately, I wasn’t able to solve today’s puzzle myself, so I’ve asked my friend for help. The task was again about exponential growth, very similar to the day 6 puzzle. However, I wasn’t able to grasp how to keep things from growing this time.
As you may remember, in the lanternfish puzzle, I’ve figured out, that if we use frequencies on current fish, we obtain their counters, and counts of fish with those counters respectively.
It was only a matter of time to notice the pattern with which lanternfish counters change.
Today’s task was very similar, but the puzzle itself lead me in the wrong direction. To explain what’ve happened let’s parse the input, as I initially did:
day13> (ns day14 (:require [clojure.string :as str]))
nil
day14> (def example-input "NNCB
CH -> B
HH -> N
CB -> H
NH -> C
HB -> C
HC -> B
HN -> C
NN -> C
BH -> H
NC -> B
NB -> B
BN -> B
BB -> N
BC -> B
CC -> N
CN -> C")
#'day14/example-input
day14> (defn read-input []
(let [lines (->> example-input
str/split-lines)
polymer (first lines)
recipes (drop 2 lines)]
{:polymer (seq polymer)
:recipes (reduce #(let [[pattern replacement] (str/split %2 #"\s+->\s+")]
(conj %1 [(seq pattern) (seq (str (first pattern) replacement))]))
{} recipes)}))
#'day14/read-input
day14> (read-input)
{:polymer (\N \N \C \B),
:recipes
{(\C \H) (\C \B),
(\N \N) (\N \C),
(\H \C) (\H \B),
(\N \C) (\N \B),
(\N \H) (\N \C),
(\C \N) (\C \C),
(\N \B) (\N \B),
(\B \C) (\B \B),
(\B \B) (\B \N),
(\B \H) (\B \H),
(\C \C) (\C \N),
(\H \N) (\H \C),
(\C \B) (\C \H),
(\H \B) (\H \C),
(\B \N) (\B \B),
(\H \H) (\H \N)}}
As you can see, I’ve pre-computed the replacements. I did it because the task said, that the patterns overlap, and “the second element of one pair is the first element of the next pair”. So I’ve realized, that we can ditch the third letter completely, and we’ll be “fine”. You can see that this assumption is correct:
day14> (def recipes (:recipes (read-input)))
#'day14/recipes
day14> (str/join (mapcat #(recipes % %) (partition-all 2 1 (:polymer (read-input)))))
"NCNBCHB"
day14> (str/join (mapcat #(recipes % %) (partition-all 2 1 *1)))
"NBCCNBBBCBHCB"
day14> (str/join (mapcat #(recipes % %) (partition-all 2 1 *1)))
"NBBBCNCCNBBNBNBBCHBHHBCHB"
day14> (str/join (mapcat #(recipes % %) (partition-all 2 1 *1)))
"NBBNBNBBCCNBCNCCNBBNBBNBBBNBBNBBCBHCBHHNHCBBCBHCB"
However, it is also growing exponentially.
Now, in order to fix this, we need to look at this polymer string as a set of pairs.
We’re already working with it as a set of pairs here, since we’re using partitioning, but these pairs grow with the string, and as you may remember from the lanterfish task, we were able to solve it with frequencies function:
day14> (frequencies (partition 2 1 "NNCB"))
{(\N \N) 1, (\N \C) 1, (\C \B) 1}
day14> (frequencies (partition 2 1 "NCNBCHB"))
{(\N \C) 1, (\C \N) 1, (\N \B) 1, (\B \C) 1, (\C \H) 1, (\H \B) 1}
day14> (frequencies (partition 2 1 "NBBBCNCCNBBNBNBBCHBHHBCHB"))
{(\C \H) 2, (\N \C) 1, (\C \N) 2, (\N \B) 4, (\B \C) 3, (\B \B) 4,
(\B \H) 1, (\C \C) 1, (\H \B) 3, (\B \N) 2, (\H \H) 1}
day14> (frequencies (partition 2 1 "NBBNBNBBCCNBCNCCNBBNBBNBBBNBBNBBCBHCBHHNHCBBCBHCB"))
{(\H \C) 3, (\N \C) 1, (\N \H) 1, (\C \N) 3, (\N \B) 9, (\B \C) 4, (\B \B) 9,
(\B \H) 3, (\C \C) 2, (\H \N) 1, (\C \B) 5, (\B \N) 6, (\H \H) 1}
day14> (frequencies (partition 2 1 "NBBNBBNBBBNBBNBBCNCCNBBBCCNBCNCCNBBNBBNBBNBBNBBNBNBBNBBNBBNBBNBBCHBHHBCHBHHNHCNCHBCHBNBBCHBHHBCHB"))
{(\C \H) 6, (\H \C) 1, (\N \C) 3, (\N \H) 1, (\C \N) 6, (\N \B) 19, (\B \C) 8,
(\B \B) 19, (\B \H) 3, (\C \C) 3, (\H \N) 1, (\H \B) 8, (\B \N) 15, (\H \H) 3}
day14> (frequencies (partition 2 1 "NBBNBBNBBNBBNBBNBNBBNBBNBBNBBNBBCCNBCNCCNBBNBNBBCNCCNBBBCCNBCNCCNBBNBBNBBNBBNBBNBBNBBNBBNBBNBBNBBBNBBNBBNBBNBBNBBNBBNBBNBBNBBNBBCBHCBHHNHCBBCBHCBHHNHCNCHBCCNBCBHCBBCBHCBBNBBNBBCBHCBHHNHCBBCBHCB"))
{(\C \H) 1, (\H \C) 9, (\N \C) 4, (\N \H) 3, (\C \N) 10, (\N \B) 41, (\B \C) 12, (\B \B) 42,
(\B \H) 9, (\C \C) 6, (\H \N) 3, (\C \B) 14, (\H \B) 1, (\B \N) 34, (\H \H) 3}
As can be seen, even though the polymer string grows exponentially, the result of partitioning and counting all of them grows much slower in size. This was the first thing I’ve thought about when I saw the growth rate, and remembered day 6. And even though such a brute-force approach worked on the input, it was a wrong approach, as part two asked to compute 40 iterations. So I’ve kinda knew how to fix it, I mean, we just need to find a way to maintain such kind of table by hand, and we’ll be done in no time. But my earlier mistake prevented me from doing it. And that mistake was in the algorithm I’ve written for parsing the input.
Part two (struggle)
As you can see, I’ve precomputed all input and output patterns, but the task specifically mentioned that the letters are inserted in between, and I totally forgot that. Let’s look into the pairs again:
day14> (partition 2 1 "NNCB")
((\N \N) (\N \C) (\C \B))
Now, if we replace these patterns, with our old method, we’ll get these patterns:
day14> (partition 2 1 "NCNBCHB")
((\N \C) (\C \N) (\N \B) (\B \C) (\C \H) (\H \B))
Now, let’s replace original patterns, as suggested by the task:
day14> (->> "NNCB"
(partition 2 1)
(mapcat '{(\N \N) (\N \C \N)
(\N \C) (\N \B \C)
(\C \B) (\C \H \B)})
(partition 2 1))
((\N \C) (\C \N) (\N \N) (\N \B) (\B \C) (\C \C) (\C \H) (\H \B))
By doing it this way we get extra pairs that should not be there.
These pairs are (N N) and (C C), as these are the points of overlapping, which can be illustrated like this:
NCN
||NBC
||||CHB
|||||||
vvvvvvv
NCNBCHB
If we remove overlapping pairs we’ll get the correct result:
((\N \C) (\C \N) (\N \B) (\B \C) (\C \H) (\H \B))
What we need to notice here, is that this method above can be used to generate all possible pairs without overlapping.
To do so we need to translate a pair into two pairs.
For example, the (N C) pair is transformed into two pairs (N B) and (B C) as this is just the same as (N [B) C].
Doing it this way, we get the correct amount of pairs from the get-go:
day14> (->> "NNCB"
(partition 2 1)
(map '{(\N \N) [(\N \C) (\C \N)]
(\N \C) [(\N \B) (\B \C)]
(\C \B) [(\C \H) (\H \B)]})
flatten
(partition 2))
((\N \C) (\C \N) (\N \B) (\B \C) (\C \H) (\H \B))
That’s the bit of information that I couldn’t figure out myself. To be completely honest, even while writing it, I’m not sure if I understood the task correctly in the first place. The overlapping point suggests that I’m correct. On the other hand the same result can be constructed like this:
N N C B
^ ^ ^
| | |
C B H
We’re literally inserting new letters between existing letters, which is a totally different approach but it also works.
So in order to solve this task, we need to take a list of pairs, and transform each into two more pairs, as shown above. But instead of storing these pairs in a list, we can use a hashmap, that stores their counts. Additionally to that, we need a separate hashmap for counting inserted letters. On each step, we see how many instances of the given pair were there, and insert that many letters into the hash table. We convert a pair to two more pairs and insert as many of each into another hash table. This repeats until needed amount of iterations have passed:
day14> (defn solve [n {:keys [polymer recipes]}]
(loop [n n
letters (frequencies polymer)
pairs (frequencies (partition 2 1 polymer))]
(if (> n 0)
(let [[letters pairs]
(reduce (fn [[letters pairs]
[[a b :as pair] n]]
(let [letter (recipes pair)
add (fnil (partial + n) 0)]
[(update letters letter add)
(-> pairs
(update [a letter] add)
(update [letter b] add))]))
[letters {}]
pairs)]
(recur (dec n) letters pairs))
[letters pairs])))
#'day14/solve
day14> (solve 1 {:polymer (seq "NNCB")
:recipes '{(\N \N) \C
(\N \C) \B
(\C \B) \H}})
[{\N 2, \C 2, \B 2, \H 1},
{[\N \C] 1, [\C \N] 1, [\N \B] 1, [\B \C] 1, [\C \H] 1, [\H \B] 1}]
Day 14 thoughts
I was a bit frustrated by this task, but it’s OK. I know that such tasks are my weakness, and it’s good that I’ve managed to finish them, even with a bit of help. A small ambiguity of the task was a bit problematic, but I’ve also failed to see the correct transformation.
Day 15 - Chiton
We’ve almost reached the exit of the cave! But there’s another problem, the walls are getting closer together, and the walls are covered with chitons, and we need to find the safest way so we wouldn’t damage any. Our input is a map of risk values, and we need to reach the bottom right coordinate:
1163751742
1381373672
2136511328
3694931569
7463417111
1319128137
1359912421
3125421639
1293138521
2311944581
The highlighted numbers are the shortest path with the lowest risk level total of 40.
Our task is to find such a path.
Well… Now I’m completely lost! I’ve never written a path-finding algorithm before, and unfortunately the university where I studied completely skipped anything related to graphs. I’m not sure why, though, as I was studying to become a bare-metal programmer, maybe they don’t need graphs, I don’t know. But we need some kind of algorithm to deal with this as a graph of points with weights. After a bit of searching, I’ve found that the Dijkstra’s algorithm is likely what I need.
Now, this algorithm works something like this (or at least how I understand it):
- We choose the first node with the lowest value and mark it as visited
- Next, we choose neighbor nodes and select the one which has a lower weight.
- If this node is the end node, we exit, if not we mark it as visited and freeze its weight to the sum of previous weights up to this node and node’s weight.
- We repeat the process, changing frozen weights if the new weight is smaller than the current one.
A better explanation can be found on the Wikipedia page I’ve linked, so if you’re interested, I suggest you read it there, as I could mess the explanation in some places. Let’s start by parsing the input:
day14> (ns day15 (:require [aoc-commons :refer [parse-long slurp-lines]]))
nil
day15> (defn read-input []
(->> "inputs/day15-ex"
slurp-lines
(map seq)
(mapv #(mapv parse-long %))))
#'day15/read-input
day15> (read-input)
[[1 1 6 3 7 5 1 7 4 2]
[1 3 8 1 3 7 3 6 7 2]
[2 1 3 6 5 1 1 3 2 8]
[3 6 9 4 9 3 1 5 6 9]
[7 4 6 3 4 1 7 1 1 1]
[1 3 1 9 1 2 8 1 3 7]
[1 3 5 9 9 1 2 4 2 1]
[3 1 2 5 4 2 1 6 3 9]
[1 2 9 3 1 3 8 5 2 1]
[2 3 1 1 9 4 4 5 8 1]]
Nice. Now, we need to implement the algorithm. The Wikipedia page has some pseudo-code examples, and also mentions a priority queue. The algorithm actually computes the path, but we’re only interested in the total path weight, so we can potentially make it simpler:
day15> (defn dijkstra [world end]
(loop [points (sorted-set [0 [0 0]]) ; our priority queue
visited #{}]
(let [[total [x y] :as point] (first points)]
(if (= [x y] end)
total ; total is the weight up to this point
(let [visited (conj visited [x y]) ; we only care about visited points,
points (reduce ; but not their weights
(fn [paths [new-x new-y]]
(if-let [risk (and (not (visited [new-x new-y]))
(get-in world [new-x new-y]))]
(conj paths [(+ total risk) [new-x new-y]])
paths))
(disj points point)
[[(dec x) y] [(inc x) y]
[x (inc y)] [x (dec y)]])]
(recur points visited))))))
#'day15/dijkstra
day15> (dijkstra (read-input) [9 9])
40
Maybe not the best implementation, but it works! And it computes the correct value, so that’s good.
We use sorted-set as our priority queue, as its semantics match our needs perfectly.
Elements are ordered, and getting first element returns the smallest one.
We store points in the following format [weight [point-x point-y]], which can be easily sorted by the set implementation.
Plugging the real input also works out correctly, let’s see part two now.
Part two
Part two says that the cave is actually a lot bigger! But we need to compute the rest of the cave ourselves.
To do so, we need to take the current cave and repeat it five times to the right.
Each repetition has each value increased by 1 and values greater than 9 overlap back starting from 1 again.
For example, if we had a cave with a single [0 0] coordinate with a weight 8 after repeating the first column five times we would get this:
89123
Now we need to repeat this row five times downwards to get the completed cave:
89123
91234
12345
23456
34567
We need to write such function and feed it our current input, then find the same path from top left to bottom right. First, let’s write a function that does the correct addition, overlapping values as described:
day15> (defn add-to-field [field x]
(let [add-to-row
(fn [row]
(mapv #(let [x (+ % x)]
(if (> x 9)
(- x 9)
x))
row))]
(mapv add-to-row field)))
#'day15/add-to-field
day15> (add-to-field [[4 5] [6 7]] 5)
[[9 1] [2 3]]
Next, we need to repeat the original world four times to the right, adding 1, 2, 3, 4 to the original one on each repetition.
Then repeat this new world four times down, adding the same numbers:
day15> (defn extend-field [input]
(let [new-world (reduce (fn [world n]
(let [new-world (add-to-field input n)]
(mapv #(into %1 %2) world new-world)))
input (range 1 5))]
(reduce (fn [world n]
(let [new-world (add-to-field new-world n)]
(into world new-world)))
new-world (range 1 5))))
#'day15/extend-field
day15> (extend-field [[8]])
[[8 9 1 2 3]
[9 1 2 3 4]
[1 2 3 4 5]
[2 3 4 5 6]
[3 4 5 6 7]]
Exactly as in the example. Now, we can plug the real input, and see if it works:
day15> (let [world (extend-field (read-input))
end-x (dec (count (first world)))
end-y (dec (count world))]
(dijkstra world [end-x end-y]))
315
And indeed it does.
Day 15 thoughts
The first part was very interesting. I’m very new to this kind of stuff, and learning about Dijkstra’s algorithm surely was very useful. The second part was a bit too easy, as the only change was that we needed to compute the new field. But I suppose that perhaps someone tried to use some other path-finding algorithm, which was checking all possible paths, so similarly to the previous day, it would have choked on the increased field. Luckily for us, our implementation performed well.
Day 16 - Packet Decoder
We’ve finally left the caves! This is such a relief, no more walls full of Chitons, or volcanic activity. And since we’re out of the caves, we’re able to receive a transmission to our submarine!
The transmission is encoded with the Buoyancy Interchange Transmission System (BITS) and is represented in hexadecimal. It’s a continuous stream of the packets, and each packet has a fixed header format:
- First three bits encode the packet version
- Next three bits encode packet ID
Packets with an ID of 4 are value packets and can be processed by checking the 7th bit.
If the 7th bit is 1 we read four bits, and check the next bit.
If this bit is yet again equal to 1, we read four more bits and check the fifth.
This repeats until the fifth bit is equal to 0, meaning that this is the last portion of the packet, so we need to read only 4 more values.
Let’s write function to read a stream using the logic so far:
day15> (ns day16 (:require [clojure.string :as str]))
nil
day16> (def hex-to-binary
{\0 "0000", \1 "0001", \2 "0010", \3 "0011",
\4 "0100", \5 "0101", \6 "0110", \7 "0111",
\8 "1000", \9 "1001", \A "1010", \B "1011",
\C "1100", \D "1101", \E "1110", \F "1111"})
#'day16/hex-to-binary
day16> (defn parse-binary [b]
(Long/parseLong (str/join b) 2))
#'day16/parse-binary
day16> (defn read-version-or-id [packet]
(let [[ver-or-id packet] (split-at 3 packet)]
[(parse-binary ver-or-id) packet]))
#'day16/read-version-or-id
day16> (defn read-value [packet]
(loop [[continue? a b c d & packet] packet
v ""]
(if (= \1 continue?)
(recur packet
(str v a b c d))
[(parse-binary (str v a b c d)) packet])))
#'day16/read-value
Now, suppose we have the packet D2FE28.
We convert it to the stream of bits first:
day16> (mapcat hex-to-binary "D2FE28")
(\1 \1 \0 \1 \0 \0 \1 \0 \1 \1 \1 \1 \1 \1 \1 \0 \0 \0 \1 \0 \1 \0 \0 \0)
Next, we can read it’s version and ID:
day16> (read-version-or-id *1)
[6 (\1 \0 \0 \1 \0 \1 \1 \1 \1 \1 \1 \1 \0 \0 \0 \1 \0 \1 \0 \0 \0)]
day16> (read-version-or-id (second *1))
[4 (\1 \0 \1 \1 \1 \1 \1 \1 \1 \0 \0 \0 \1 \0 \1 \0 \0 \0)]
As can be seen, each function returns the parsed value and the rest of the packet, so we can continue parsing it.
Now we can read the value, since this is the package with ID of 4:
day16> (read-value (second *1))
[2021 (\0 \0 \0)]
This returns the value of 2021 and the rest of the packet stream, which we do not care about right now.
There’s a second type of packet, which are operator packets.
They’re totally different beasts though.
Packets with IDs that are not equal to 4, have the next bit after ID as length ID.
The length ID can be either 0, meaning that we need to read the next N bits or 1 meaning that we need to process the next N packets.
Let’s implement the function that will read length ID and the length itself:
day16> (defn read-length [packet]
(let [[type & packet] packet
id (parse-binary (str type))
length (case id 0 15 1 11)
[length packet] (split-at length packet)]
[id (parse-binary length) packet]))
#'day16/read-length
day16> (mapcat hex-to-binary "38006F45291200")
(\0 \0 \1 \1 \1 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \1 \1 \0 \1 \1 \1 \1 \0 \1 \0 \0 \0 \1 \0 \1 \0 \0 \1 \0 \1 \0 \0 \1 \0 \0 \0 \1 \0 \0 \1 \0 \0 \0 \0 \0 \0 \0 \0 \0)
day16> (read-version-or-id *1)
[1 (\1 \1 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \1 \1 \0 \1 \1 \1 \1 \0 \1 \0 \0 \0 \1 \0 \1 \0 \0 \1 \0 \1 \0 \0 \1 \0 \0 \0 \1 \0 \0 \1 \0 \0 \0 \0 \0 \0 \0 \0 \0)]
day16> (read-version-or-id (second *1))
[6 (\0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \1 \1 \0 \1 \1 \1 \1 \0 \1 \0 \0 \0 \1 \0 \1 \0 \0 \1 \0 \1 \0 \0 \1 \0 \0 \0 \1 \0 \0 \1 \0 \0 \0 \0 \0 \0 \0 \0 \0)]
day16> (read-length (second *1))
[0 27 (\1 \1 \0 \1 \0 \0 \0 \1 \0 \1 \0 \0 \1 \0 \1 \0 \0 \1 \0 \0 \0 \1 \0 \0 \1 \0 \0 \0 \0 \0 \0 \0 \0 \0)]
Here it correctly reads the length and its type. Now we can implement the function that will process the stream of packets until it finishes. We need to store the packet versions in order to solve the first part:
day16> (defn process-packet-stream [packets]
(let [[ver packets] (read-version-or-id packets)
[id packets] (read-version-or-id packets)]
(if (= id 4)
(let [[_ packets] (read-value packets)]
[[ver] packets])
(let [[length-id length packets] (read-length packets)
[vers packets]
(loop [length length
packets packets
inner-vers [ver]]
(if (> length 0)
(let [len-before (count packets)
[vers packets] (process-packet-stream packets)]
(recur (case length-id
0 (- length (- len-before (count packets)))
1 (dec length))
packets
(into inner-vers vers)))
[inner-vers packets]))]
[vers packets]))))
#'day16/process-packet-stream
day16> (process-packet-stream (mapcat hex-to-binary "A0016C880162017C3686B18A3D4780"))
[[5 1 3 7 6 5 2 2] (\0 \0 \0 \0 \0 \0 \0)]
Seems to work so far!
This function recursively calls itself when if finds an operator packet.
It determines the number of packages it needs to process recursively based on the lendth-id.
We get the list of versions as the first value of the returned vector.
Now we just need to reduce it with addition, and we’ll get our answer.
This grants us the first gold star, let’s see what’s in part two!
Part two
So now, ununexpectedly we need to actually use values and operators stored in packets. Operators are determined by the packet ID, and are as follows:
0- summation1- product2- minimum value3- maximum value5- greater than6- smaller than7- equal to
Applied to all the data in the packet. Seems easy to implement, as we just need to store values during recursion similarly to versions, and call some function based on ID when exiting the recursion step:
day16> (defn process-packet-stream [packets]
(let [[ver packets] (read-version-or-id packets)
[id packets] (read-version-or-id packets)]
(if (= id 4)
(let [[val packets] (read-value packets)]
[[ver] [val] packets])
(let [[length-id length packets] (read-length packets)
[vers vals packets]
(loop [length length
packets packets
inner-vers [ver]
inner-vals []]
(if (> length 0)
(let [len-before (count packets)
[vers vals packets] (process-packet-stream packets)]
(recur (case length-id
0 (- length (- len-before (count packets)))
1 (dec length))
packets
(into inner-vers vers)
(into inner-vals vals)))
[inner-vers inner-vals packets]))]
(case id
0 [vers [(reduce + vals)] packets]
1 [vers [(reduce * vals)] packets]
2 [vers [(apply min vals)] packets]
3 [vers [(apply max vals)] packets]
5 [vers [(if (apply > vals) 1 0)] packets]
6 [vers [(if (apply < vals) 1 0)] packets]
7 [vers [(if (apply = vals) 1 0)] packets])))))
#'day16/process-packet-stream
day16> (process-packet-stream (mapcat hex-to-binary "A0016C880162017C3686B18A3D4780"))
[[5 1 3 7 6 5 2 2] [54] (\0 \0 \0 \0 \0 \0 \0)]
Checking the second return value grants us the second gold star.
Day 16 thoughts
Today’s task was pretty simple, but the description was very convoluted. I think I’ve spent most of the time figuring out what bits are responsive to what kind of information and so on. So I really have a question. I mean, yes, English is not my first language, but I think I’m pretty decent, as I can write, read and talk freely (albeit with some accent, and grammar issues). But I’ve spent good 20 minutes only to understand the task fully, but the leader board for this day shows people completing both parts in under 10 minutes! I understand, that there are people who compete with others and take it pretty seriously, but how do you read so fast?! I mean, yesterday’s task with pathfinding algorithm and terrain generation was completed in under 4 minutes. Four minutes! This is some serious speed programming.
I’ll try to search for the recording, but I’m generally interested in the thought process of people who’re able to solve these tasks so fast. The tasks are not too complicated, but the speed still amazes me. If you know some of the videos like this feel free to send me a link, I’ll be interested.
Day 17 - Trick Shot
Today we need to send the probe into the ocean trench. To do that we need to fire the probe with certain x and y velocities, which are integers. For the first part, we need to find such velocity that the probe reaches maximum y position while still reaching the trench.
For example, for given trench coordinates:
target area: x=20..30, y=-10..-5
Shooting the probe with 6,3 velocities, we end up in the trench:
| 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 … 29 30
---+-----------------------------------------------------------------------------
5| . . . . . . . . . . . . . . . # . . # . . . . … . .
4| . . . . . . . . . . . # . . . . . . . . # . . … . .
3| . . . . . . . . . . . . . . . . . . . . . . . … . .
2| . . . . . . # . . . . . . . . . . . . . . # . … . .
2| . . . . . . . . . . . . . . . . . . . . . . . … . .
1| . . . . . . . . . . . . . . . . . . . . . . . … . .
0| S . . . . . . . . . . . . . . . . . . . . # . … . .
-1| . . . . . . . . . . . . . . . . . . . . . . . … . .
-2| . . . . . . . . . . . . . . . . . . . . . . . … . .
-3| . . . . . . . . . . . . . . . . . . . . . . . … . .
-4| . . . . . . . . . . . . . . . . . . . . . # . … . .
-5| . . . . . . . . . . . . . . . . . . . . T T T … T T
-6| . . . . . . . . . . . . . . . . . . . . T T T … T T
-7| . . . . . . . . . . . . . . . . . . . . T T T … T T
-8| . . . . . . . . . . . . . . . . . . . . T T T … T T
-9| . . . . . . . . . . . . . . . . . . . . T # T … T T
-10| . . . . . . . . . . . . . . . . . . . . T T T … T T
Here we reach the highest y coordinate of 5, and our probe crosses the trench in [-9,21]
However, if the probe was fired at a different speed it might go through the trench, but never probe it, so we must ensure, that the probe touches the trench at least once.
To actually find the highest y coordinate, we only need the minimum y value of the trench, which in this case is -10, and take the triangular number from it:
(- 10) * (1 + (- 10)) / 2 = 45
Which equals to 45.
This also works for the real input, and it works because the bottom coordinate of the trench is the last one we’re able to hit, therefore we need to iterate it accordingly to how the velocity changes.
And the velocity changes by one, which means that ascending from position -10 + 1 will be (-9)+(-8)+...+(-1).
The x coordinate doesn’t matter here, as in ballistics x and y motions are independent from each other:

Figure 1: Image from Wikipedia article on the Projectile Motion
So it doesn’t matter what x velocity the probe has, as long as we only care for maximum height.
Part two
Now we need to find all unique velocities, that will make the probe end up in the trench.
To do so we need to test all velocities for a range of velocities.
For x it would be [0,max_x], and for y it is [-abs(min_y),abs(min_y)).
So we need to implement the function, that determines if the given velocity vector will end up in the trench, based on how velocity changes over time.
The y velocity simply decreases over time without a cap, so we will just use dec function.
For x velocity value we move towards zero from both positive and negative values:
day16> (ns day17)
nil
day17> (defn update-x-vel [vel]
(cond (< vel 0) (inc vel)
(> vel 0) (dec vel)
:else 0))
#'day17/update-x-vel
day17> (update-x-vel 0)
0
day17> (update-x-vel 2)
1
day17> (update-x-vel -2)
-1
Now we can write the movement function:
day17> (defn solve
([x-vel y-vel min-x max-x min-y max-y]
(when (solve 0 x-vel 0 y-vel min-x max-x min-y max-y)
[x-vel y-vel]))
([x x-vel y y-vel min-x max-x min-y max-y]
(cond (and (<= min-x x max-x) (<= min-y y max-y))
true
(or (and (< y min-y) (< y-vel 0))
(> x max-x)
(and (< x min-x) (= x-vel 0)))
nil
:else
(recur (+ x x-vel) (update-x-vel x-vel)
(+ y y-vel) (dec y-vel)
min-x max-x
min-y max-y))))
#'day17/solve
This function is quite simple, it checks if current x and y coordinates are within the trench.
If they are we return the velocity vector.
If not, we move one more step.
But we stop completely when we overshoot the trench by x or y, or when we could not reach it by y or x when the respective velocity is not enough.
Let’s try it:
day17> (solve 6 3 20 30 -10 -5)
[6 3]
So it works for the example input, where we knew such velocity. Now we need to find all such velocities. For that we need to check the ranges, I’ve talked about earlier:
day17> (defn solve-all [[min-x max-x min-y max-y]]
(->> (for [xv (range (inc max-x))
yv (range (- (Math/abs min-y)) (Math/abs min-y))]
(solve xv yv min-x max-x min-y max-y))
(filter some?)
distinct))
#'day17/solve-all
day17> (solve-all [20 30 -10 -5])
([6 0] [6 1] [6 2] [6 3] [6 4] [6 5] [6 6] [6 7] [6 8] [6 9] [7 -1] [7 0]
[7 1] [7 2] [7 3] [7 4] [7 5] [7 6] [7 7] [7 8] [7 9] [8 -2] [8 -1] [8 0]
[8 1] [9 -2] [9 -1] [9 0] [10 -2] [10 -1] [11 -4] [11 -3] [11 -2] [11 -1]
[12 -4] [12 -3] [12 -2] [13 -4] [13 -3] [13 -2] [14 -4] [14 -3] [14 -2]
[15 -4] [15 -3] [15 -2] [20 -10] [20 -9] [20 -8] [20 -7] [20 -6] [20 -5]
[21 -10] [21 -9] [21 -8] [21 -7] [21 -6] [21 -5] [22 -10] [22 -9] [22 -8]
[22 -7] [22 -6] [22 -5] [23 -10] [23 -9] [23 -8] [23 -7] [23 -6] [23 -5]
[24 -10] [24 -9] [24 -8] [24 -7] [24 -6] [24 -5] [25 -10] [25 -9] [25 -8]
[25 -7] [25 -6] [25 -5] [26 -10] [26 -9] [26 -8] [26 -7] [26 -6] [26 -5]
[27 -10] [27 -9] [27 -8] [27 -7] [27 -6] [27 -5] [28 -10] [28 -9] [28 -8]
[28 -7] [28 -6] [28 -5] [29 -10] [29 -9] [29 -8] [29 -7] [29 -6] [29 -5]
[30 -10] [30 -9] [30 -8] [30 -7] [30 -6] [30 -5])
day17> (count *1)
112
We only need to check values in between those because others will overshoot. Plugging the real input results in the correct answer, and we get the second gold star.
Day 17 thoughts
It was an interesting discovery that we can just calculate a triangular number for the first part, and I’m a bit upset that I had to compute the second one by using almost a brute force solution. But it works, and it’s not slow, so it’s not a big deal. I wasn’t able to solve this task fast though, as I wasn’t sure how to properly approach it, and how to determine all velocities that needed to be checked. So I guess, people from the top of the table are pretty smart, as they’ve solved this task in 4.5 minutes. I mean, it’s possible to solve the first part quite fast, as it doesn’t require any coding at all, just to do the math, which isn’t really hard. But I’ve needed to figure this out first, and then write code for the second part.
Day 18
This weekend is quite different from the last one! Tasks are much harder this time, and I’m also out of the town without my laptop. So I’m writing this on my phone!5 I’m doing it in Emacs, installed inside Termux, which thankfully has a lot of packages, that allow me to continue working even without a laptop. And the craziest thing, that I was solving the eighteenth task on my phone too! JDK17 was recently added as a package to the main Termux repository, and this means that Clojure now can be installed directly on my phone too. This means, that I have Clojure, Emacs, and CIDER everywhere I go!
Sure, typing on the phone’s keyboard is not as pleasant as on a physical one, but I’m pretty decent at it. I was developing things on my phone for years now - almost half of the commits on my GitHub profile before the pandemic were made from the phone. So solving the AoC puzzle on the phone should not be too hard to do, especially since I can use full-blown Clojure IDE!
So let’s jump right into it!
Snailfish
Our journey to finding the sleigh keys may finally be over! Some snailfish says that they’ve seen the sleigh keys, but they won’t tell us where. Unless we’ll help them with their math homework. I guess we can, we really need every bit of information about these keys, and math should not be too complicated, given how deep we’re are already. But it turns out that snailfish numbers aren’t like our numbers at all. Each number is represented as a pair:
[1,2]
[[1,2],3]
[1,[2,3]]
[[1,2] [3,4]]
And so on. These numbers nest arbitrarily, but there are exactly two numbers in a pair.
Now, this looks like trees! Such tree can be represented by using an open square bracket as a node marker, and numbers or other square brackets will be leafs:
[
/ \
1 [
/ \
2 3
This is great because Clojure has a library for navigating tree-like structures, called zippers! I’ve always wanted to look at zippers, but unfortunately, there were no tasks that required tree traversal.
Now, back to the numbers.
The addition of two numbers is simple enough.
To add two numbers [1,1]+[2,2] we just wrap them into another set pf square brackets: [[1,1],[2,2]].
However, it’s not all.
Numbers need to be reduced when some conditions apply.
A number must be reduced if it has any pair nested at fourth level: [[[[[1,2],3],4],5],6].
In the case of this number, the [1,2] pair is deep enough to “explode”.
An explosion of a pair is the first reduction step that we need to perform.
To do so we must add the left number from the pair with the first left number outside the pair if any.
The same is done to the right one.
Then the pair itself is replaced with a single 0.
So for this number [[[[[1,2],3],4],5],6] the steps are:
[1,2]needs to explode.1has no number on the left, so nothing happens with it. The number so far:[[[[[1,2],3],4],5],6].2has3on the right side, so we replace3with5. The number so far:[[[[[1,2],5],4],5],6]- Addition was completed, and now the
[1,2]is replaced with0. Resulting number:[[[[0,5],4],5],6].
The same happens if there are only numbers from the left side, but no addition is done for the right number. And if there are numbers on both sides, they both are replaced by the sum, and the pair itself is replaced with zero.
The second reduction step happens when any number is greater than 9.
Such a number splits into its own pair.
The left part is computed by dividing the number by 2 and rounding it down.
For the right part, the process is the same but rounded up.
So a number like [10,3] becomes [[5,5],3], and a number like [11,3] becomes [[5,6],3].
There’s one more thing for the reduction process. There are only two steps, but we must repeat the first one until there’s nothing left to explode. Then, if there are any numbers that can be split, we split the leftmost one. Then we go to the previous step. If the number remains unchanged in both steps, it means we’ve reached the end of the reduction process.
Phew, snailfish numbers are surely complicated. But since we, hopefully, understood the reduction process, we can begin by reading the input:
day17> (ns day18
(:require [clojure.zip :as z]
[clojure.string :as str]))
nil
day18> (defn read-input []
(-> "inputs/day18"
slurp
(str/join "[]")
read-string))
#'day18/read-input
Wait, that’s cheating!
You might say that, but thankfully, Clojure can read snailfish numbers directly, as these are valid syntax!
Commas are ignored by the reader (thanks, Rich!) and square brackets represent vectors.
So to read the list of numbers into a list of vectors, we only need to join the "[]" string with a string of numbers as a separator!
This is a neat trick:
day18> (str/join "," "abcd") ; comma is a separator
"a,b,c,d"
day18> (str/join "abcd" "[]") ; "abcd" is a separator now
"[abcd]"
Now we can begin the homework.
The first thing we need to do is to find the leftmost pair that needs to explode. To do that, we can use zippers, and track how deep we’ve descended into the tree with a simple loop:
day18> (defn exploding-node [root]
(loop [level 0
loc (z/vector-zip root)]
(cond (and (= level 4) (z/branch? loc))
loc
(z/branch? loc)
(recur (inc level) (z/down loc))
(z/right loc) (recur level (z/right loc))
:else
(let [[level loc]
(loop [level (dec level)
loc (z/up loc)]
(cond (and (= level 0) (not (z/right loc)))
[level nil]
(not (z/right loc))
(recur (dec level) (z/up loc))
:else
[level (z/right loc)]))]
(when loc
(recur level loc))))))
#'day18/exploding-node
This function accepts a number and uses the vector-zip function on it.
Then we traverse the tree, tracking when we go down and up.
Once we’ve found the needed node, we return it’s location as a zipper:
day18> (exploding-node [[[[[1,2],3],4],5],6])
[[1 2]
{:l [],
:pnodes
[[[[[[1 2] 3] 4] 5] 6] [[[[1 2] 3] 4] 5] [[[1 2] 3] 4] [[1 2] 3]],
:ppath
{:l [],
:pnodes [[[[[[1 2] 3] 4] 5] 6] [[[[1 2] 3] 4] 5] [[[1 2] 3] 4]],
:ppath
{:l [],
:pnodes [[[[[[1 2] 3] 4] 5] 6] [[[[1 2] 3] 4] 5]],
:ppath
{:l [], :pnodes [[[[[[1 2] 3] 4] 5] 6]], :ppath nil, :r (6)},
:r (5)},
:r (4)},
:r (3)}]
Now, we need a way of finding numbers to the left and to the right of this pair.
Since there’s no number to the left right now, let’s write the find-right function first:
day18> (defn find-right [loc]
(when-not (= (z/root loc) (z/node loc))
(if-let [right (z/right loc)]
(if (z/branch? right)
(loop [loc right]
(if (z/branch? loc)
(recur (z/next loc))
loc))
right)
(recur (z/up loc)))))
#'day18/find-right
This function accepts a location in the tree and starts from it.
We only do the search for nodes that are not the root ones, as the root has no numbers outside of it.
First, we check if there’s a number to the right of the current location.
If not we simply ascend.
If there is a number, it means that we never need to ascend again, so we check whether it is a branch?, meaning that we’re looking at another pair.
If not, we’ve found our number, so we return it.
If it is a branch we loop moving to the next element until we find one that is not a branch.
Let’s try it:
day18> (find-right (exploding-node [[[[[1,2],3],4],5],6]))
[3
{:l [[1 2]],
:pnodes
[[[[[[1 2] 3] 4] 5] 6] [[[[1 2] 3] 4] 5] [[[1 2] 3] 4] [[1 2] 3]],
:ppath
{:l [],
:pnodes [[[[[[1 2] 3] 4] 5] 6] [[[[1 2] 3] 4] 5] [[[1 2] 3] 4]],
:ppath
{:l [],
:pnodes [[[[[[1 2] 3] 4] 5] 6] [[[[1 2] 3] 4] 5]],
:ppath
{:l [], :pnodes [[[[[[1 2] 3] 4] 5] 6]], :ppath nil, :r (6)},
:r (5)},
:r (4)},
:r nil}]
The return value is another location in the tree.
Now, let’s do the same for the left number.
It’s a bit trickier, as we need to find the right number on the left side.
E.g. for this number [[7,6],[[[[5,4],3],2],1]] the exploding pair is [5,4], and the left number is 6:
day18> (defn find-left [loc]
(when-not (= (z/root loc) (z/node loc))
(if-let [left (z/left loc)]
(if (z/branch? left)
(loop [loc (z/next left)]
(let [loc (z/rightmost loc)]
(if (z/branch? loc)
(recur (z/next loc))
loc)))
left)
(recur (z/up loc)))))
#'day18/find-left
day18> (z/node (exploding-node [[7,6],[[[[5,4],3],2],1]]))
[5 4]
day18> (z/node (find-left (exploding-node [[7,6],[[[[5,4],3],2],1]])))
6
This function also ascends until there’s something on the left side, but then it descends to the rightmost element of each level.
It returns the location of the left number, which we render with the node function, to keep the output short.
Now we can find the required numbers:
day18> (let [loc (exploding-node [[7,6],[[[[5,4],3],2],1]])
left (find-left loc)
right (find-right loc)]
(println (format "exploding pair: %s\nleft: %s\nright: %s"
(z/node loc)
(z/node left)
(z/node right))))
exploding pair: [5 4]
left: 6
right: 3
nil
Good!
Now let’s implement the explosion step of the reduction process.
To do that, we need to change the tree.
Thankfully, zippers, while being immutable, support tree editing.
To change the tree, we need to find a location that is ready to be exploded and side numbers.
The structure of the numbers tells us that there will always be at least one number to the side.
So we can check which one is there, replace it with the sum, and then replace the location itself with 0:
day18> (defn explode [root]
(if-let [loc (exploding-node root)]
(let [[a b] (z/node loc)
left (find-left loc)
right (find-right loc)]
(-> (cond (not left) (z/edit right + b)
(not right) (z/edit left + a)
:else (-> left
(z/edit + a)
z/root
exploding-node
find-right
(z/edit + b)))
z/root
exploding-node
(z/replace 0)
z/root))
root))
#'day18/explode
day18> (explode [[7,6],[[[[5,4],3],2],1]])
[[7 11] [[[0 7] 2] 1]]
In case where both numbers are available we have to do additional searches.
Unfortunately zippers are new to me, so maybe there’s a more optimal way of doing this, but I wasn’t able to find it.
My guess was to use the path function, but it seems that there’s no way to navigate to a certain location in the changed zipper, but to search it from the root again.
Maybe I could write such function, but the semantics of the task allow me to just find the same exploding node from the root again.
This number explodes correctly, and we now have a number that can be split.
Let’s write a function, that finds the leftmost number that is greater than 9:
day18> (defn splittable-node [root]
(loop [loc (z/vector-zip root)]
(when-not (z/end? loc)
(cond (z/branch? loc)
(recur (z/next loc))
(> (z/node loc) 9)
loc
:else
(recur (z/next loc))))))
#'day18/splittable-node
day18> (z/node (splittable-node *2))
11
Seems correct. Now let’s write another function, that splits the given location:
day18> (defn split [root]
(if-let [loc (splittable-node root)]
(-> loc
(z/edit (juxt #(int (Math/floor (/ % 2)))
#(int (Math/ceil (/ % 2)))))
z/root)
root))
#'day18/split
day18> (split [[7 11] [[[0 7] 2] 1]])
[[7 [5 6]] [[[0 7] 2] 1]]
It’s always so pleasant when you can use the juxt function.
Now we only need to implement addition with all necessary reduction steps:
day18> (defn sum [a b]
(loop [x [a b]]
(let [x' (explode x)]
(if (= x' x)
(let [x' (split x')]
(if (= x x')
x'
(recur x')))
(recur x')))))
#'day18/sum
day18> (sum [7,6] [[[[5,4],3],2],1])
[[7 [5 6]] [[[0 7] 2] 1]]
This loop will explode the number until the number remains the same as before the explosion.
Then it will split a single number, and repeat.
If the number is unchanged after a split, means we’ve finished.
To actually compute the answer, we need to implement another function that calculates the magnitude. To do that we need to multiply the left part of the pair by 3 and the right pair by 2, then add them:
day18> (defn magnitude' [loc]
(cond (z/end? loc)
(z/root loc)
(z/branch? loc)
(let [loc (z/next loc)
left (magnitude' loc)
right (magnitude' (z/right loc))]
(z/replace loc (+ (* 3 (z/node left)) (* 2 (z/node right)))))
:else
loc))
#'day18/magnitude'
day18> (defn magnitude [root]
(z/node (magnitude' (z/vector-zip root))))
#'day18/magnitude
Finally, given that we have a list of numbers we need to add together, we can use reduce on it with our sum function, and then compute the magnitude for the final answer:
day18> (defn part-1 [input]
(->> input
(reduce sum)
magnitude))
#'day18/part-1
day18> (part-1 (read-input))
3763
This grants us the first gold star!
Part two
For the second part, we need to find the largest magnitude across all numbers.
The catch is that snailfish addition is not commutative, which means that a+b is not necessarily equal to b+a, so we need to check all variants.
It’s quite simple in Clojure, thanks to for:
day18> (defn part-2 [input]
(->> (for [a input
b input]
(when-not (= a b)
(magnitude (sum a b))))
(filter some?)
(apply max)))
#'day18/part-2
day18> (part-2 (read-input))
4664
Here checking if the numbers are the same to avoid adding them.
This introduces elements that are nil in our final list, so we filter them out.
Then we just find the max value, and get the second gold star!
Day 18 thoughts
Phew, this was challenging! Writhing all of this on the phone, while simultaneously learning about zippers, is definitively something. The task itself wasn’t as hard, but there were some tricky parts with finding the correct number, which was extremely hard to debug, especially on the phone’s screen:
Day 19
Unfortunately, I wasn’t able to solve this task. I seriously couldn’t understand what I even need to do with all these coordinates. Maybe I’ll solve it later, though I highly doubt that I’ll come back to any missed day or previous events for that matter.
Well, a continuous 18 days streak for this year’s AoC seems good to me. The previous year ended at day 15, which I had not completed, and couldn’t find any willpower to continue.
Maybe tomorrow’s task will be more understandable, and so I’ll just skip a single day. We’ll see how it goes.
Day 20 - Trench Map
With the scanners fully deployed (totallyDay 19][totally]]), we now can compute the map of the trench. But when we get the image from the scanners, it looks like a random noise (I wonder why, perhaps because of the extremely convoluted positioning in the previous task?). So we need to enhance the image with a certain algorithm.
The algorithm consists of the string, that specifies how to enhance a particular image pixel. The example input consists of such string and an image:
..#.#..#####.#.#.#.###.##.....###.##.#..###.####..#####..#....#..#..##..###..######.###...####..#..#####..##..#.#####...##.#.#..#.##..#.#......#.###.######.###.####...#.##.##..#..#..#####.....#.#....###..#.##......#.....#..#..#..##..#...##.######.####.####.#.#...#.......#..#.#.#...####.##.#......#..#...##.#.##..#...##.#.##..###.#......#.#.......#.#.#.####.###.##...#.....####.#..#..#.##.#....##..#.####....##...##..#...#......#.#.......#.......##..####..#...#.#.#...##..#.#..###..#####........#..####......#..#
#..#.
#....
##..#
..#..
..###
To determine the value of the pixel we need to look at all pixels around this pixel and construct a binary number.
For simplicity let’s replace # with 1 and . with 0, and mark pixels that surround the middle one:
1 0 0 1 0
1 [0 0 0] 0
1 [1 0 0] 1
0 [0 1 0] 0
0 0 1 1 1
This forms a binary number 000100010, which is 34 in decimal.
So, to enhance the current pixel, we need to take value from the enhancement string at this position, which happens to be # or 1.
We then repeat this for each pixel on the image.
However, the image is actually infinite, and we need to process it as a whole.
This task looks like a cellular automaton once again, as the image basically grows between iterations, as some previously dark pixels will become light or dark, depending on the surroundings. Let’s start by reading the input. First, I’d like to transform the image itself to a table of coordinates as keys, and brightness as values:
user> (ns day20
(:require [clojure.string :as str]))
nil
day20> (defn img->coords [img]
(reduce-kv (fn [img y line]
(reduce-kv (fn [img x c]
(assoc img [x y] (if (= c \#) 1 0)))
img (vec line)))
(sorted-map)
(str/split img #"\n")))
#'day20/img->coords
day20> (img->coords "#..\n.#.\n..#")
{[0 0] 1,
[0 1] 0,
[0 2] 0,
[1 0] 0,
[1 1] 1,
[1 2] 0,
[2 0] 0,
[2 1] 0,
[2 2] 1}
We’ll also parse the enhancement string as a vector of zeroes and ones:
day20> (defn read-input []
(let [[enh img] (-> "inputs/day20"
slurp
(str/split #"\n\n"))]
{:enhance (mapv #(if (= % \#) 1 0) enh)
:image (img->coords img)}))
#'day20/read-input
Now, when we have our image and enhancement string parsed, we can write a function that will enhance a given image. First, we need to write a function, that reads the pixel’s value and values of all surrounding pixels. It then computing an index in the enhancement string, and gets the enhancement value from that string:
day20> (defn enhancement [{:keys [image enhance]} [x y] default]
(nth enhance
(-> (for [y [(dec y) y (inc y)]
x [(dec x) x (inc x)]]
(get image [x y] default))
str/join
(Long/parseLong 2))))
#'day20/enhancement
Note that I’m using an explicit default value, but let’s forget about it for now.
Our image is infinite, and we only have a portion of it, so we need to extend the image somehow.
To do that we’ll just decrease the minimum image coordinate by 1 and increase the maximum by 1.
We’ll do it during the enhancement process, so the new image will become larger automatically:
day20> (defn enhance [{:keys [enhance image] :as img} step]
(let [points (keys image)
[min-x min-y] (first points)
[max-x max-y] (last points)
default (cond (zero? step) 0
(even? step) (peek enhance)
:else (first enhance))]
{:image (into
(sorted-map)
(for [x (range (dec min-x) (+ max-x 2))
y (range (dec min-y) (+ max-y 2))]
[[x y] (enhancement img [x y] default)]))
:enhance enhance}))
#'day20/enhance
This default value is the bane of my existence.
I’ve spent hours trying to understand why it is needed, and why at the first step it must be 0.
So I assume, that it is zero (or . in case of the task) on the first step is because we start with an empty image.
Then we need to check what step we’re on and enhance using the first or the last value in the string.
This is because when we expand the image new pixels are always zeroes, and thus will be converted to ones.
The final thing needed to do is to find all light pixels and count them - easy:
day20> (defn solve [n input]
(->> (reduce #(enhance %1 %2) input (range n))
:image
vals
(reduce +)))
#'day20/solve
day20> (solve 2 (read-input))
5619
Now, the craziest thing is that this solution will work the real input even without the (zero? step) case, but will not work for example one!
Here:
day20> (defn enhance [{:keys [enhance image] :as img} step]
(let [points (keys image)
[min-x min-y] (first points)
[max-x max-y] (last points)
default (cond #_#_(zero? step) 0
(even? step) (peek enhance)
:else (first enhance))]
{:image (into
(sorted-map)
(for [x (range (dec min-x) (+ max-x 2))
y (range (dec min-y) (+ max-y 2))]
[[x y] (enhancement img [x y] default)]))
:enhance enhance}))
#'day20/enhance
day20> (solve 2 (read-input))
5619
day20> (defn read-input []
(let [[enh img] (-> "inputs/day20-example"
slurp
(str/split #"\n\n"))]
{:enhance (mapv #(if (= % \#) 1 0) enh)
:image (img->coords img)}))
#'day20/read-input
day20> (def example-input (read-input))
#'day20/example-input
day20> (solve 2 example-input)
34
It yields 34 instead of expected 35 but works for real input regardless.
Part two is just the same as part one, just with 50 steps instead of two:
day20> (solve 50 example-input)
5209
day20> (solve 50 (read-input)) ; using the original function
20122
Keep in mind that this is without the (zero? step), so 5209 is the wrong answer for example input.
But 20122 is the correct value for the real input.
Consider the same but with original enhance function:
day20> (solve 2 example-input)
35
day20> (solve 50 example-input)
3351
day20> (solve 50 (read-input))
20122
And I’ve tested this on several inputs - it works, and I don’t understand why, honestly.
Day 20 thoughts
While working on this puzzle on the first development iteration I wrote an algorithm that always used zeroes as extended values. It worked on the example input, and on the real input but only for part one! And when I’ve tested it on different inputs it didn’t work, so I mean, this task is extremely finicky. Especially since I got the right answer for part one with the wrong code on one input non-example, but it didn’t work for another.
Day 21 - Dirac Dice
As it seems, when there are neither any problems to solve outside of the submarine nor inside of it, the computer still wants to give us some trouble! This time, though it is just a mere desire to play a game with us.
The game is simple, we have a circular board with 10 spaces. We throw dice three times and move our pawn amount of rolls added together. The score is initially zero, and each time we step on a certain space, we add this space to the score.
As a practice game, a computer offers us deterministic dice, which always roll in increasing order from 1 to 100.
And each player rolls three times, which means that the first one will roll 1, 2, and 3, moving forward by 6 places.
The second player will roll 4, 5, and 6, and move forward by 15 places.
The game ends when the first player reaches 1000 or more points.
Let’s start by parsing an input:
day20> (ns day21
(:require [clojure.string :as str]
[aoc-commons :refer [parse-long]]))
nil
day21> (defn read-input []
(reduce #(let [[_ player pos] (re-find #".*(\d+).*(\d+)" %2)
player (parse-long player)
pos (parse-long pos)]
(assoc %1 player
{:pos pos
:score 0}))
(sorted-map)
(->> "inputs/day21"
slurp
str/split-lines)))
#'day21/read-input
day21> (read-input)
{1 {:pos 3, :score 0}, 2 {:pos 4, :score 0}}
I’m kinda lazy right now, so this code, while ugly, works for me. It returns a sorted map of players, which we will iterate. I’m using a map as it is easier to update than a vector, and the order is deterministic. Now we can jump into solving part one.
First thing we need to do is to form the infinite sequence of rolls:
day21> (set! *print-length* 10)
10
day21> (map (partial apply +) (partition 3 (cycle (range 1 101))))
(6 15 24 33 42 51 60 69 78 87 ...)
I’m generating a sequence of numbers from 1 to 100 and then using the cycle function, to make this sequence repeat infinitely.
Next, we partition it into groups of three, and add each one, effectively changing the game so there’s only one roll per player.
Now we can just reduce this sequence, by switching players.
day21> (defn step [[throws players turns] [i player]]
(let [pos (inc (mod (+ (:pos player) (dec (first turns))) 10))
score (+ (:score player) pos)]
((if (>= score 1000)
reduced
identity)
[(+ throws 3)
(update players i
assoc
:pos pos
:score score)
(rest turns)])))
#'day21/step
This is a reducing function, that accepts the current amount of throws, players map, and sequence of turns as its first argument.
As the second argument, it accepts a player.
We simply calculate a new position, and score, and check if the score is greater than 1000.
If it is we use reduced to terminate the reduce, and return the final result.
Now we only need to loop until any player wins:
day21> (defn part-1 [input]
(loop [throws 0
rolls (map (partial apply +) (partition 3 (cycle (range 1 101))))
players input]
(let [[throws players turns] (reduce step [throws players rolls] players)]
(if (some #(>= (:score (second %)) 1000) players)
(* throws (apply min (map (comp :score second) players)))
(recur throws
turns
players)))))
#'day21/part-1
day21> (part-1 (read-input))
995904
This was easy, but I suspect that the next part will be about something like computing the most optimal winning sequence of rolls or computing all possible games. So such a plain approach probably will not work.
Part two
Part two puts a twist on the game by changing the dice to Dirac dice.
This dice, when rolled, splits the universe to all possible outcomes of a single roll.
Since this dice has three sides it means that on each roll there are three new universes, in each of which the result is 1, 2, and 3 respectively.
The game still plays by rolling three times per player, which means on each turn the universe splits into 27 universes.
The task mentions that player one wins in 444356092776315 universes, so there’s no way we’ll be able to calculate all of that by brute force.
On the other hand, we can. If you know what the Fibonacci sequence is, you may also know that there are two ways of doing it - by using iteration and with recursion. Recursive approach is quite simple:
day21> (defn fib [n]
(if (or (= n 0) (= n 1))
1
(+' (fib (- n 1)) (fib (- n 2)))))
#'day21/fib
day21> (fib 4)
5
day21> (map fib (range 10))
(1 1 2 3 5 8 13 21 34 55)
day21> (time (fib 42))
"Elapsed time: 7221.764838 msecs"
433494437
The problem with this approach is that it splits into two branches on each number, and each branch re-computes the result over and over again:
.------------ fib 5 ------------.
/ \
.---- fib 4 ----. .- fib 3 -.
/ \ / \
.- fib 3 -. fib 2 fib 2 fib 1
/ \ / \ / \ |
fib 2 fib 1 fib 1 fib 0 fib 1 fib 0 1
/ \ | | | | |
fib1 fib 0 1 1 1 1 1
| |
1 1
As can be seen, fib 2 is computed 3 times, fib 1 is computed 1 times, and so on.
For bigger numbers, this tree becomes very wide.
But there’s an easy fix for that - we can memoize function calls, and cut this tree to a single branch:
fib 5
/ \
fib 4 memo
/ \
fib 3 memo
/ \
fib 2 memo
/ \
fib1 fib 0
| |
1 1
Now, all duplicate branches are computed from memoized values. Sure, this uses more memory, but makes this variant very efficient:
day21> (def fib
(memoize
(fn [n]
(if (or (= n 0) (= n 1))
1
(+' (fib (- n 1)) (fib (- n 2)))))))
#'day21/fib
day21> (time (fib 42))
"Elapsed time: 1.176521 msecs"
433494437
day21> (time (fib 200))
"Elapsed time: 1.449005 msecs"
453973694165307953197296969697410619233826N
This will be our strategy for the second part. We’ll write the task as if we really were to play all games, but we’ll just memoize already played ones and cut the tree.
day21> (def play
(memoize
(fn [players turn]
(loop [[roll & rolls] (for [a [1 2 3] b [1 2 3] c [1 2 3]] [a b c])
wins {}]
(if roll
(let [roll (apply + roll)
p (players turn)
pos (inc (mod (+ (:pos p) (dec roll)) 10))
score (+ (:score p) pos)]
(if (> score 20)
(recur rolls (update wins turn (fnil inc 0)))
(let [players (update players turn assoc :pos pos :score score)
wins' (play players
(inc (mod turn (count players))))]
(recur rolls (merge-with + wins wins')))))
wins)))))
#'day21/play
I use for to compute a sequence of rolls for each of 27 universes.
And wins are stored in the wins table, where each player has their own score.
If the game is won we just return new wins state, and go into the next game.
If the game isn’t won we go into parallel universes, and that’s where memoization comes into play.
Since we memoize players with their states, and a turn, we know for sure if we’ve played some game, as the game’s result is memoized.
The turns are cycled between players, meaning on each call of play we increase the player’s number until there are no more players, e.g. 1, 2, 1, 2.
This will work with more players, even though there are no more players in the task.
Now we only need to determine who wins more:
day21> (defn part-2 [input]
(apply max (vals (play input 1))))
#'day21/part-2
day21> (part-2 (read-input))
193753136998081
Phew, that’s a lot of games!
Day 21 thoughts
This was interesting indeed. I don’t know from where exactly I remember the memoization trick for the Fibonacci sequence, but this knowledge surely helped me to understand the problem. Other than that, this was pretty straightforward to solve.
Day 22 - Reactor Reboot
Today we need to reboot the reactor.
Unfortunately, the reactor is made out of cuboids that can intersect in 3D space.
First part requires us to figure out which cubes are on or off, but only for the range of -50 to 50 for each coordinate.
This is a grand total of 1030301 cubes, so we can solve this by brute force approach, which I’m absolutely sure will not work for the second part, but I did it anyway.
The second part simply wants us to process a whole range of cubes, and I’ve thought about it for a bit and decided not to waste any more time on this. Honestly, the tasks lately are becoming really tedious and boring while not being really challenging. Seriously, there already were three tasks that are like “hey here’s an exponential growth, try it on a small sample, then do it on a whole one”. This one is no different.
I mean, the second part is essentially about keeping all ranges and subtracting overlapping ranges that are off from all currently existing ranges. The only challenge here is to properly write the detection and subtracting code. Then the remaining ranges need to be computed into the total amount of cubes. I just don’t want to waste time on this, I’ve seen such type of task three (or more) times already during this event only.
To be completely fair, I really wanted to complete this event, but as it seems I will not do it. I’m losing steam and don’t feel invested enough with the quite low variety of tasks this year.
Day 23 - Amphipod
And they did it again. Today’s task is yet again “try this easy part, that can be solved by brute force. Yes, correct… now suffer from all this extra data you need to process” type of task. Our task is to move every Amphipod into their room:
############# #############
#...........# #...........#
###B#C#B#D### --> ###A#B#C#D###
#A#D#C#A# #A#B#C#D#
######### #########
Each Amphipod is marked as a letter, and we can only place letters above # symbols.
Furthermore, letters can only go into their own room, and only if there are no letters from other rooms.
In other words, these cases are invalid:
############# #############
#..B........# #.....C.....#
###.#C#B#D### ###.#B#B#D###
#A#D#C#A# #A#D#C#A#
######### #########
B stands over B entered a room that still contains D
the room's exit which don't belong to that room
We have a hallway with two pockets on each side, each of which can contain two letters at most, and we also have three more positions between rooms.
Letters can’t go over each other, so we need to avoid deadlocks.
The other catch is that each letter has a different move cost.
A costs 1 point, B costs 10, C costs 100, and D costs 1000.
This means that we should try to never move D more than once, and we can probably do some extra moves of A and B, but not too much.
Overall this looks like a Hanoi Tower type of task, but instead of moving sorted pillars of disks from one pole to another pole, we need to sort discs between poles. In the case of the following example, there aren’t too many ways we can solve it, because of deadlocks and move costs. But I’m not in the coding mood today, so let’s use a neural network instead, and let it solve the task for us without any line of code. By neural network, I mean my own brain ofc.
So I’ve tried it 4 times, and figured that the following sequence of moves leads to the most optimal result:
############# ############# ############# ############# ############# ############# ############# ############# ############# ############# ############# ############# #############
#...........# #..........A# #.........CA# #.........CA# #.A.......CA# #.A.B.....CA# #.A.B......A# #.A.B......A# #.A........A# #.A........A# #.A........A# #..........A# #...........#
###B#B#D#A### ###B#B#D#.### ###B#B#D#.### ###B#B#.#.### ###B#B#.#.### ###B#.#.#.### ###B#.#.#.### ###B#.#C#.### ###B#.#C#.### ###.#B#C#.### ###.#B#C#D### ###.#B#C#D### ###A#B#C#D###
#D#C#A#C# #D#C#A#C# #D#C#A#.# #D#C#A#D# #D#C#.#D# #D#C#.#D# #D#C#C#D# #D#.#C#D# #D#B#C#D# #D#B#C#D# #.#B#C#D# #A#B#C#D# #A#B#C#D#
######### ######### ######### ######### ######### ######### ######### ######### ######### ######### ######### ######### #########
0 3 300 5000 7 20 50 50 30 40 9000 3 9
Adding these together we get the correct result 14512.
But the second part will not be that easy, because it adds two more rows to the rooms, with the preset pattern:
#############
#...........#
###B#B#D#A###
#D#C#B#A# <-- these
#D#B#A#C# <-- ones
#D#C#A#C#
#########
Now there a lot more moves to consider.
Well, given that the first column contains all three D letters, we can safely assume that we will have at very least three moves 11000 worth of points.
Two C letters in the last room are likely to be moved after we already fully empty the second room, so that’s another 1400 points.
Then we move A letters to the packets, finish C room, and then D room, finishing with A room.
Well, that’s just a guess based on the whole situation, so let’s try this:
############# ############# ############# ############# ############# ############# ############# ############# ############# ############# ############# ############# ############# ############# ############# ############# ############# ############# ############# ############# ############# ############# ############# ############# ############# ############# ############# ############# ############# #############
#...........# #..........D# #B.........D# #BA........D# #BA.......AD# #BA.B.....AD# #BA.B.....AD# #BA.B...B.AD# #BA.B...B.AD# #BA.....B.AD# #BA.......AD# #BA.......AD# #B....A...AD# #.....A...AD# #A........AD# #AA.......AD# #AA...A...AD# #AA...A...AD# #AA...A...AD# #AA...A.A..D# #AA...A.A...# #AA...A....A# #AA.......AA# #AA.......AA# #AA.......AA# #AA.......AA# #A........AA# #.........AA# #..........A# #...........#
###B#B#D#A### ###B#B#.#A### ###B#B#.#A### ###B#B#.#A### ###B#B#.#A### ###B#.#.#A### ###B#.#.#A### ###B#.#.#A### ###B#.#.#A### ###B#.#.#A### ###B#.#.#A### ###.#.#.#A### ###.#.#.#A### ###.#B#.#A### ###.#B#.#A### ###.#B#.#.### ###.#B#.#.### ###.#B#.#.### ###.#B#C#.### ###.#B#C#.### ###.#B#C#.### ###.#B#C#.### ###.#B#C#.### ###.#B#C#.### ###.#B#C#.### ###.#B#C#D### ###.#B#C#D### ###.#B#C#D### ###.#B#C#D### ###A#B#C#D###
#D#C#B#A# #D#C#B#A# #D#C#.#A# #D#C#.#A# #D#C#.#A# #D#C#.#A# #D#.#.#A# #D#.#.#A# #D#.#.#A# #D#.#.#A# #D#.#.#A# #D#B#.#A# #D#B#.#A# #D#B#.#A# #D#B#.#A# #D#B#.#A# #D#B#.#.# #D#B#C#.# #D#B#C#.# #D#B#C#.# #D#B#C#.# #D#B#C#.# #D#B#C#.# #.#B#C#.# #.#B#C#D# #.#B#C#D# #.#B#C#D# #.#B#C#D# #A#B#C#D# #A#B#C#D#
#D#B#A#C# #D#B#A#C# #D#B#A#C# #D#B#.#C# #D#B#.#C# #D#B#.#C# #D#B#.#C# #D#.#.#C# #D#.#C#C# #D#.#C#C# #D#B#C#C# #D#B#C#C# #D#B#C#C# #D#B#C#C# #D#B#C#C# #D#B#C#C# #D#B#C#C# #D#B#C#.# #D#B#C#.# #D#B#C#.# #D#B#C#.# #D#B#C#.# #D#B#C#.# #D#B#C#D# #.#B#C#D# #.#B#C#D# #.#B#C#D# #A#B#C#D# #A#B#C#D# #A#B#C#D#
#D#C#A#C# #D#C#A#C# #D#C#A#C# #D#C#A#C# #D#C#.#C# #D#C#.#C# #D#C#C#C# #D#C#C#C# #D#.#C#C# #D#B#C#C# #D#B#C#C# #D#B#C#C# #D#B#C#C# #D#B#C#C# #D#B#C#C# #D#B#C#C# #D#B#C#C# #D#B#C#C# #D#B#C#.# #D#B#C#.# #D#B#C#D# #D#B#C#D# #D#B#C#D# #D#B#C#D# #D#B#C#D# #.#B#C#D# #A#B#C#D# #A#B#C#D# #A#B#C#D# #A#B#C#D#
######### ######### ######### ######### ######### ######### ######### ######### ######### ######### ######### ######### ######### ######### ######### ######### ######### ######### ######### ######### ######### ######### ######### ######### ######### ######### ######### ######### ######### #########
0 5000 80 8 7 20 800 60 900 50 60 50 4 50 5 8 5 700 700 2 6000 3 4 11000 11000 11000 5 5 9 9
This gives us the total of 47544 points:
However, this is not the correct answer.
I’ve noticed that instead of moving B to the left pocket, which I’ve assumed would be the most optimal move, I can instead move it to the right pocket.
This will add up later, but we can solve this in a bit fewer moves of A letters:
############# ############# ############# ############# ############# ############# ############# ############# ############# ############# ############# ############# ############# ############# ############# ############# ############# ############# ############# ############# ############# ############# ############# ############# ############# ############# #############
#...........# #..........D# #.........BD# #A........BD# #AA.......BD# #AA.....B.BD# #AA.....B.BD# #AA.B...B.BD# #AA.B...B.BD# #AA.....B.BD# #AA.....B.BD# #AA.......BD# #AA.......AD# #AA...A...AD# #AA...A...AD# #AA...A...AD# #AA...A.A..D# #AA...A.A...# #AA...A....A# #AA.......AA# #AA.......AA# #AA.......AA# #AA.......AA# #A........AA# #.........AA# #..........A# #...........#
###B#B#D#A### ###B#B#.#A### ###B#B#.#A### ###B#B#.#A### ###B#B#.#A### ###B#.#.#A### ###B#.#.#A### ###B#.#.#A### ###B#.#.#A### ###B#.#.#A### ###.#.#.#A### ###.#.#.#A### ###.#B#.#.### ###.#B#.#.### ###.#B#.#.### ###.#B#C#.### ###.#B#C#.### ###.#B#C#.### ###.#B#C#.### ###.#B#C#.### ###.#B#C#.### ###.#B#C#.### ###.#B#C#D### ###.#B#C#D### ###.#B#C#D### ###.#B#C#D### ###A#B#C#D###
#D#C#B#A# #D#C#B#A# #D#C#.#A# #D#C#.#A# #D#C#.#A# #D#C#.#A# #D#.#.#A# #D#.#.#A# #D#.#.#A# #D#.#.#A# #D#.#.#A# #D#B#.#A# #D#B#.#A# #D#B#.#.# #D#B#C#.# #D#B#C#.# #D#B#C#.# #D#B#C#.# #D#B#C#.# #D#B#C#.# #.#B#C#.# #.#B#C#D# #.#B#C#D# #.#B#C#D# #.#B#C#D# #A#B#C#D# #A#B#C#D#
#D#B#A#C# #D#B#A#C# #D#B#A#C# #D#B#.#C# #D#B#.#C# #D#B#.#C# #D#B#.#C# #D#.#.#C# #D#.#C#C# #D#.#C#C# #D#B#C#C# #D#B#C#C# #D#B#C#C# #D#B#C#C# #D#B#C#.# #D#B#C#.# #D#B#C#.# #D#B#C#.# #D#B#C#.# #D#B#C#.# #D#B#C#D# #.#B#C#D# #.#B#C#D# #.#B#C#D# #A#B#C#D# #A#B#C#D# #A#B#C#D#
#D#C#A#C# #D#C#A#C# #D#C#A#C# #D#C#A#C# #D#C#.#C# #D#C#.#C# #D#C#C#C# #D#C#C#C# #D#.#C#C# #D#B#C#C# #D#B#C#C# #D#B#C#C# #D#B#C#C# #D#B#C#C# #D#B#C#C# #D#B#C#.# #D#B#C#.# #D#B#C#D# #D#B#C#D# #D#B#C#D# #D#B#C#D# #D#B#C#D# #.#B#C#D# #A#B#C#D# #A#B#C#D# #A#B#C#D# #A#B#C#D#
######### ######### ######### ######### ######### ######### ######### ######### ######### ######### ######### ######### ######### ######### ######### ######### ######### ######### ######### ######### ######### ######### ######### ######### ######### ######### #########
0 5000 50 9 9 40 800 40 900 50 60 50 60 5 700 700 2 6000 3 4 11000 11000 11000 5 5 9 9
This gives us 47510 points, which is less than our previous result, but still not correct.
The problem is, I don’t know if this answer is too low or too high, as the page stopped giving hints at some point, to avoid bisecting, I guess.
So I can’t verify if I’m doing it completely wrong in case this answer is too low, or I’m not doing it optimal enough if it is too high.
However, since I’m not going to write code for this task, I’ve decided to cheat. I went to the leaderboard and found the solution for this task. Funnily enough, I’ve noticed that I’m not the only one who decided to solve this task by hand, and some of these people are as high as 14th rank. Pretty impressive, as this task is not an easy one to do manually, given all possible variants.
But I’m here for the answers, and the code says that the correct answer is… 52358!
I’m not going to submit it just because someone else computed it for me, I just wanted to see if I’m not doing it optimally or not.
But wait, my solution is much more optimal than that, what the hell?
Have I made a wrong move somehow or have I misinterpreted the rules?
While doing this I’ve checked that I basically:
- never step into the tiles that are directly above the room.
- never went into the other’s letter’s room.
- never jumped over another letter.
The rule about not standing above the room is a bit vague. It explicitly says that it refers to four open places above each room, so naturally, I think it’s safe to assume that we can never stand on those. But then it also mentions: “this refers to the four open spaces in the hallway that are directly above an amphipod starting position”. So this means that we can stand on this tile when we’re not moving out of the room or what?
############# #############
#........A..# #......A....#
###B#B#D#.### ###B#B#D#.###
#D#C#B#A# #D#C#B#A#
#D#B#A#C# #D#B#A#C#
#D#C#A#C# #D#C#A#C#
######### #########
forbidden. allowed???
I guess it’s not allowed, as the rule says that “never stop on the space immediately outside any room”. I’m not sure why they decided to mention the “above an amphipod starting position” part at all. So from now on, I’ll assume that both cases are forbidden. But I never used such moves in my solution, so what exactly have I done wrong?
Turns out, I’ve forgotten about one critical rule.
You can’t move in the hallway once you’ve stopped there.
From the hallway, you can only move into the room.
And In my solution, I’m moving letter A back and forth through the hall to make room for maneuvers.
Now, this surely complicates the task.
However, it also cuts down a lot of possible moves.
So our strategy should be basically about finding optimal starting moves that occupy hallway ends and provide enough room for other letter moves. I’ve thought that it should not be that bad, but it turns out it was pretty hard. (who would have guessed?) Anyway, after about 18 tries (I’ve lost count) that ended in a deadlock one way or another, I’ve managed to do it like this:
############# ############# ############# ############# ############# ############# ############# ############# ############# ############# ############# ############# ############# ############# ############# ############# ############# ############# ############# ############# ############# ############# ############# ############# ############# #############
#...........# #B..........# #B.........D# #B........DD# #BD.......DD# #BD.......DD# #BD.C.....DD# #BD.C.C...DD# #BD.C.C...DD# #BD.C.C....D# #BD.C.C.....# #BD.C.C....B# #BD.C.C.A.AB# #BD.C...A.AB# #BD.....A.AB# #BD.......AB# #BD........B# #B.........B# #BB........B# #BB........B# #BB.B......B# #BB.B......B# #BB........B# #B.........B# #..........B# #...........#
###B#B#D#A### ###.#B#D#A### ###.#B#D#A### ###.#B#D#A### ###.#B#D#A### ###.#B#D#.### ###.#B#D#.### ###.#B#D#.### ###.#B#.#.### ###.#B#.#.### ###.#B#.#.### ###.#B#.#.### ###.#B#.#.### ###.#B#.#.### ###.#B#.#.### ###.#B#.#.### ###A#B#.#.### ###A#B#.#D### ###A#.#.#D### ###A#.#.#D### ###A#.#.#D### ###A#.#C#D### ###A#.#C#D### ###A#.#C#D### ###A#.#C#D### ###A#B#C#D###
#D#C#B#A# #D#C#B#A# #.#C#B#A# #.#C#B#A# #.#C#B#A# #.#C#B#A# #.#C#B#.# #.#C#B#.# #.#C#B#.# #.#C#B#.# #.#C#B#D# #.#C#.#D# #.#C#.#D# #.#C#.#D# #.#C#.#D# #A#C#.#D# #A#C#.#D# #A#C#.#D# #A#C#.#D# #A#.#C#D# #A#.#C#D# #A#.#C#D# #A#.#C#D# #A#.#C#D# #A#B#C#D# #A#B#C#D#
#D#B#A#C# #D#B#A#C# #D#B#A#C# #.#B#A#C# #.#B#A#C# #.#B#A#C# #A#B#A#.# #A#B#A#.# #A#B#A#.# #A#B#A#D# #A#B#A#D# #A#B#A#D# #A#B#.#D# #A#B#.#D# #A#B#C#D# #A#B#C#D# #A#B#C#D# #A#B#C#D# #A#B#C#D# #A#B#C#D# #A#.#C#D# #A#.#C#D# #A#.#C#D# #A#B#C#D# #A#B#C#D# #A#B#C#D#
#D#C#A#C# #D#C#A#C# #D#C#A#C# #D#C#A#C# #.#C#A#C# #A#C#A#C# #A#C#A#C# #A#C#A#.# #A#C#A#D# #A#C#A#D# #A#C#A#D# #A#C#A#D# #A#C#.#D# #A#C#C#D# #A#C#C#D# #A#C#C#D# #A#C#C#D# #A#C#C#D# #A#C#C#D# #A#C#C#D# #A#C#C#D# #A#.#C#D# #A#B#C#D# #A#B#C#D# #A#B#C#D# #A#B#C#D#
######### ######### ######### ######### ######### ######### ######### ######### ######### ######### ######### ######### ######### ######### ######### ######### ######### ######### ######### ######### ######### ######### ######### ######### ######### #########
0 30 10000 10000 5000 11 800 700 7000 4000 4000 60 5 500 600 7 8 8000 40 600 40 700 50 60 60 70
Which indeed computes to 52358, so the code I’ve tried was correct.
I’m not sure if there is actually more than one solution to this problem.
With all rules listed in the task, it looks like that there can be only one solution.
So the code can probably just recursively try all games and cut branches that end in a deadlock.
Anyway, we got through, and there are only two days left. I’m unsure if I’ll be able to solve the 25th day in time, as I’ll be out yet again this weekend.
Day 24
Unfortunately, I’ve decided not to solve this task. It does require reverse-engineering the given code, and I’m just not motivated enough to do that. So yet another task that needs to be done by hand is just too much for me. Sure today’s task is interesting, I’m just too exhausted to do it.
After the event ends, I’ll be removing all individual posts and will publish a single post, containing all days I’ve managed to solve. Let’s see what waits for us tomorrow and finish this.
Day 25 - Sea Cucumber
This is it. The last puzzle of the event. We’ve almost made it through. The only thing that stands between us, and the sleigh keys are two herds of sea cucumbers.
Cucumbers are constantly in the move, and our task is to simulate their behavior.
There are two herds, one that always moves east, and another one that always moves south.
They’re represented with > and v respectively:
....v.....
.>v....v..
.......>..
....v....>
On each step, first, the south herd moves one step forward, then the south herd moves one step downward.
Cucumbers can only go into the empty place, marked with a dot ., and will wait if there’s no room.
For the example above, the south herd moves first:
....v.....
.>v....v..
........>.
>...v.....
As can be seen the leftmost > couldn’t move, because there’s v standing in its way.
The second and third > cucumbers moved freely.
The third one actually crossed the gap of the field and moved to the other side, almost as if we’re in a cylindrical world.
Then the south herd moves:
..........
.>..v.....
..v....v>.
>...v.....
All three topmost v cucumbers were able to move.
However, because the moves are executed simultaneously, the bottom v could not move, as the other cucumber was still in the starting position, from its perspective.
So we basically need to implement these rules and run the simulation. I hope the second part won’t require us to run the simulation one million times on a much bigger field, otherwise, I will be very disappointed. Looking at the leaderboard, it seems that the second part took approximately six seconds to solve, so it’s either some very little derivation in the algorithm, or the requirements for the task are just bigger, but the code is so optimal that it can handle it in no time.
Ok, we actually need to write the code today, so let’s do it quickly:
user> (ns day25 (:require [aoc-commons :refer [slurp-lines transpose]]))
nil
day25> (defn read-input []
(->> "inputs/day25"
slurp-lines
(mapv vec)))
#'day25/read-input
Since there are no diagonal moves, we can restrict the problem to a single row at a time.
As we need to move a cell in the row, I think reduce-kv can do:
day25> (defn move [kind row]
(let [len (count row)]
(reduce-kv
(fn [row' i c]
(if (= c kind)
(let [pos (mod (inc i) len)]
(if (= (nth row pos) \.)
(assoc row' i \. pos kind)
row'))
row'))
row row)))
#'day25/move
day25> (move \> [\. \> \> \. \>])
[\> \> \. \> \.]
This function accepts kind of cucumber we’re moving, so we can reuse it for vertical movement as well.
And for vertical movement we will just transpose our world, and repeat the process:
day25> (defn step [world]
(->> world
(mapv (partial move \>))
transpose
(mapv (partial move \v))
transpose))
#'day25/step
The only thing left is to write a function, that will run our simulation until the world stops changing:
day25> (defn part-1 [input]
(reduce (fn [world i]
(let [world' (step world)]
(if (= world' world)
(reduced i)
world')))
input (drop 1 (range))))
#'day25/part-1
day25> (part-1 (read-input))
367
And part one is done. It was quite easy, compared to the two previous puzzles. Let’s see what awaits us in part two? I guess not.
Day 25 and event ending thoughts
Unfortunately, by the time I’ve finished the first part, I only had 44 stars. And part two unlocks only if you have 49 stars. So perhaps the last star isn’t a variation of the first part at all, but some kind of congratulations or something like that. However, I will not see what’s there unless I’ll go back and solve day 19, part two of day 22, and day 24. I’m not sure if I will, though.
The puzzle for day 25 was a joke. I’ve thought, that since this is a weekend, the task will be brutal, as was on both previous weekends. I guess it’s a holiday, and the task is not hard, so everyone could hang out with their families, friends, and so on. Well, I couldn’t - I was on a train solving and writing this on a phone yet again. It’s a bit sad that there was no part two, but I guess it’s my own fault. I couldn’t keep up with the difficulty spikes, and lost motivation over the last few days, because the variety of tasks was (IMHO) very low. Looking back at it, there definitively were interesting tasks.
As I said, my problem with this year’s event is that the variety wasn’t very big. There were three tasks with exponential growth6, that required finding a way to tame this by grouping the data in some way. Six tasks about 2D data structures7, not including two cellular automaton-like tasks8, which also were 2D. Two tasks about binary data processing9. One task for navigating trees10, and two for navigating graphs11. Two tasks could have been solved without any code fully on paper12. The rest are hard to categorize.
Probably, my favorite ones were on days 8, 11, 13, 15, 17, 18, and 20.
I really like cellular automaton type of puzzles, as they allow you to run the simulation, and even visualize it. I’ve done this the last year, and this year was no different. However, I think there were just too many tasks of this type. The fun ones were on days 11 and 20.
I really liked day 8 because it was a neat task to figure out what wire corresponds to what - kind of reverse engineering, which required you to also write a program that will unmangle the input. Unlike day 24 which was also about reverse engineering, but required no code to solve, as was shown by a lot of people in the community.
I’ve liked days 15 and 18 because they’ve taught me new things - I’ve learned the path-finding algorithm, and a library for navigating trees that I’ve long wanted to try out.
Days 13 and 17 were cool 2D tasks, which I’ve simply liked.
The tasks that I’ve really despised were tasks on days 6, 14, 19, 22, 23, and 24. I simply do not find these types of tasks fun. The challenge is also questionable, especially for the last 4 of these. They were more tedious than hard IMO.
Other than that, the event went mostly smoothly. I had some bad days where events in my life combined with the increased difficulty of tasks made me really angry (and you should never be angry about something like puzzles). Overall, if I was asked to explain my thoughts about this event in a single word, this word would be “meh”. I wanted to try to solve as many puzzles from the event as I can, and also write a post in my blog for every one of them. Maybe this was a mistake, as both solving, and writing in a single day is more exhausting than only solving a puzzle itself. I don’t think I’ll repeat this kind of format the next year if I will even participate. But if I will, I’ll probably do small writeups about days that I’ve really enjoyed instead.
I hope you’ve had fun during this event, and thank you for reading. Merry Christmas and until next year!
-
A funny coincidence: I’ve started on December 14 and completed 14 days, ending by December 28, with 28 stars. ↩︎
-
Sadly there’s no Wikipedia page for Lotto in English so, given that this game comes from Italy, I’ve linked the Italian one. The main difference from Bingo is that the winner has to mark all the numbers on the board, and the board is not a square. There’s a chance that only a single row will be fully covered, and usually, such players get a consolation prize. ↩︎
-
I’ve reordered the map items, as well as set items to match the ordering of letters, but the letters it-selves weren’t changed. ↩︎
-
Obviously, I’m overreacting here - it was kinda obvious after seeing how points formed a rectangle. ↩︎
-
I’ve edited the post on PC once I came back in town, that’s why I wasn’t able to publish it on the same day as the task. ↩︎
-
days 7, 14 and 21 ↩︎
-
days 4, 5, 9, 13, 15, and 25 ↩︎
-
days 11 and 20 (25th was also kinda) ↩︎
-
days 3 and 16 ↩︎
-
day 18 ↩︎
-
days 12 and 15 (8th was also kinda) ↩︎
-
days 23 and 24 ↩︎