Clojure on Fennel part two: immutable.fnl optimizations
- part one: persistent data structures
- part two: immutable.fnl optimizations
- part three: parsing
- part four: parsing (again)
So the next post will hopefully be about the compiler itself.
Unless I get distracted again.
Sike!
While I did some work on the compiler, I’m not feeling ready to talk about it yet. I want the post about it to be, well, more in-depth, so for now, let’s go back to immutable data structures. I got some comments on their performance, which can be summarized to “bad”.
And I agree! The performance is not great, especially when compared to plain Lua tables. However, my benchmarking process was a bit flawed, and I’ve improved it since.
This post won’t be long, but I wanted to make it anyway, to illustrate what I’m dealing with. Again, this is not the final version, I’m still working on possible optimizations as I write this, but some things have improved already, though not by much.
There were some low-hanging fruits that I could tackle:
- Vector had a local
fragmentfunction with pure arithmetic. I already have the samefragmentfunction in my bitops module that uses native rshift+band. The modulo operation is expensive. - A similar case of using bit operations instead of modulo was in HashMap’s
indexfunction. - Increased the popcount table to 256 entries instead of 16. Halves the loop iterations for typical bitmaps.
- Probably premature, but replaced most instances of
faccumulate,fcollect, etc. with plainforloops. These loops are quite hot, and Fennel compiles them to have additional assignment at each iteration. Should be free, but actually had a small impact. - More pre-allocations when creating Lua tables.
Using
[nil nil nil nil]tells the Lua compiler to pre-allocate four slots when creating the table, meaning it won’t resize once we insert elements. Tables in Lua resize by a factor of 2 and copy everything on resize, which is not great for performance. - Vector iterator is now stateful. And also fast.
- Internal fields for data structures used long, elaborate keys, which meant string comparison in certain cases of table lookup would be unnecessarily long. Again, changing them to shorter keys should not matter that much, but it did have some impact.
- HashMap branching factor was increased to 32. After some tests, it proved to be slightly better, despite what I said in my previous post. More on that later.
- Hashes are now cached in a weak table. Helps avoid re-hashing the same values at the expense of memory. Not sure how well it will scale.
- Optimized array copying for sizes less than 4 by doing direct table construction. Avoids loop overhead.
With these changes in place (and some more I omitted), here are some of the benchmarks:
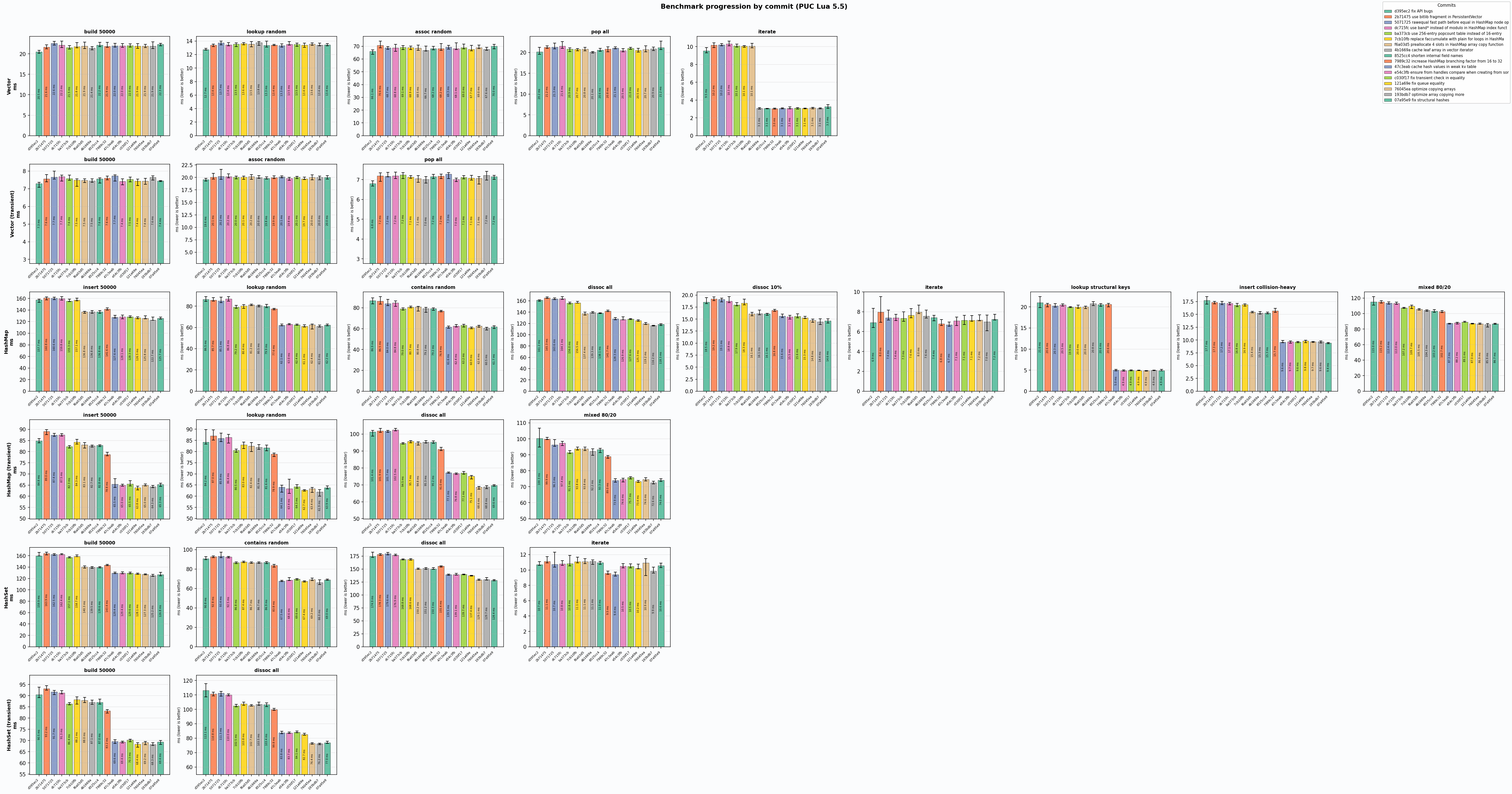
These images show per-commit changes to the performance. Really helped me track what was worth keeping, and what wasn’t.
Here’s the LuaJIT version of the benchmark:
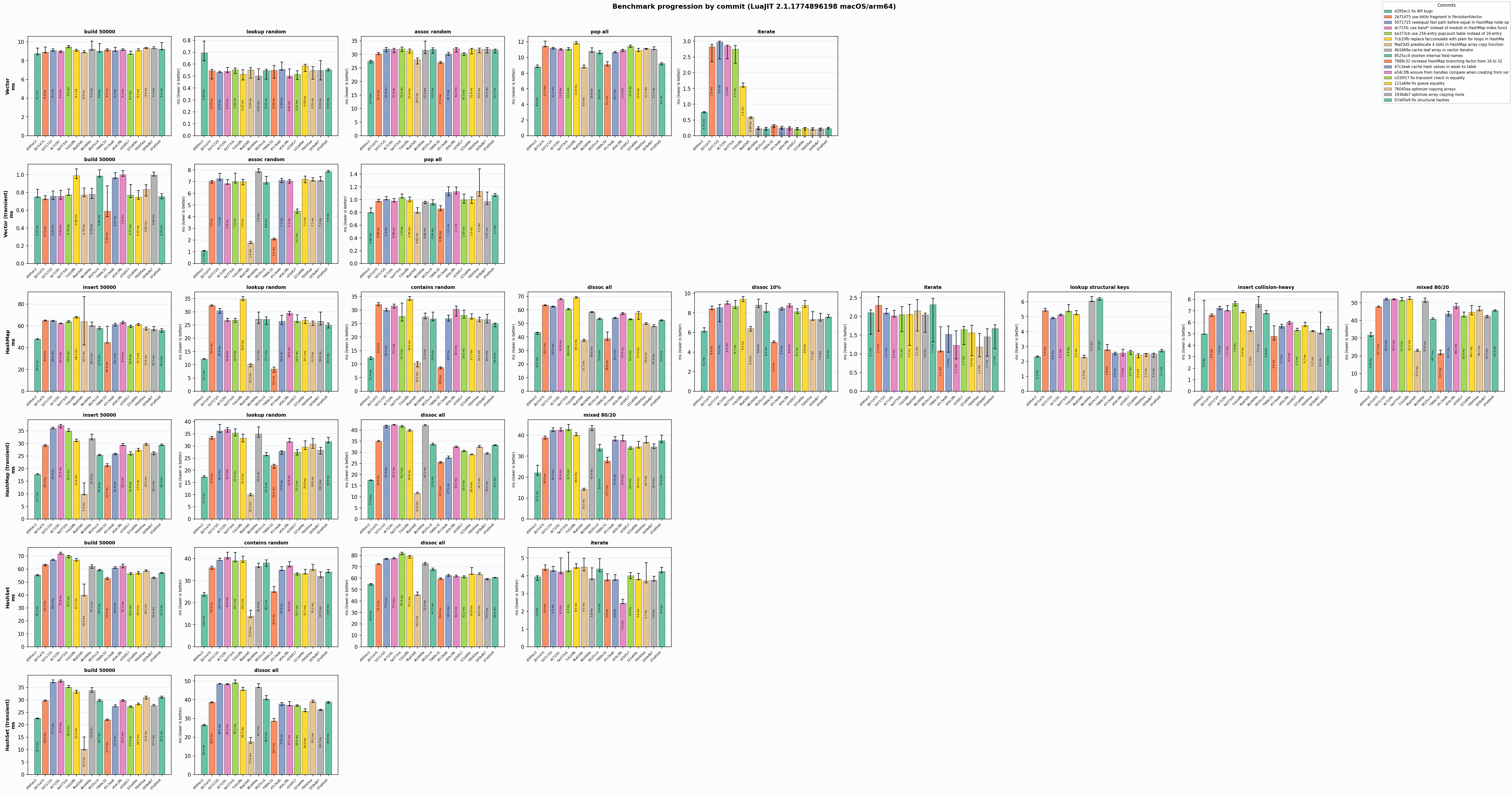
Here’s another graph:
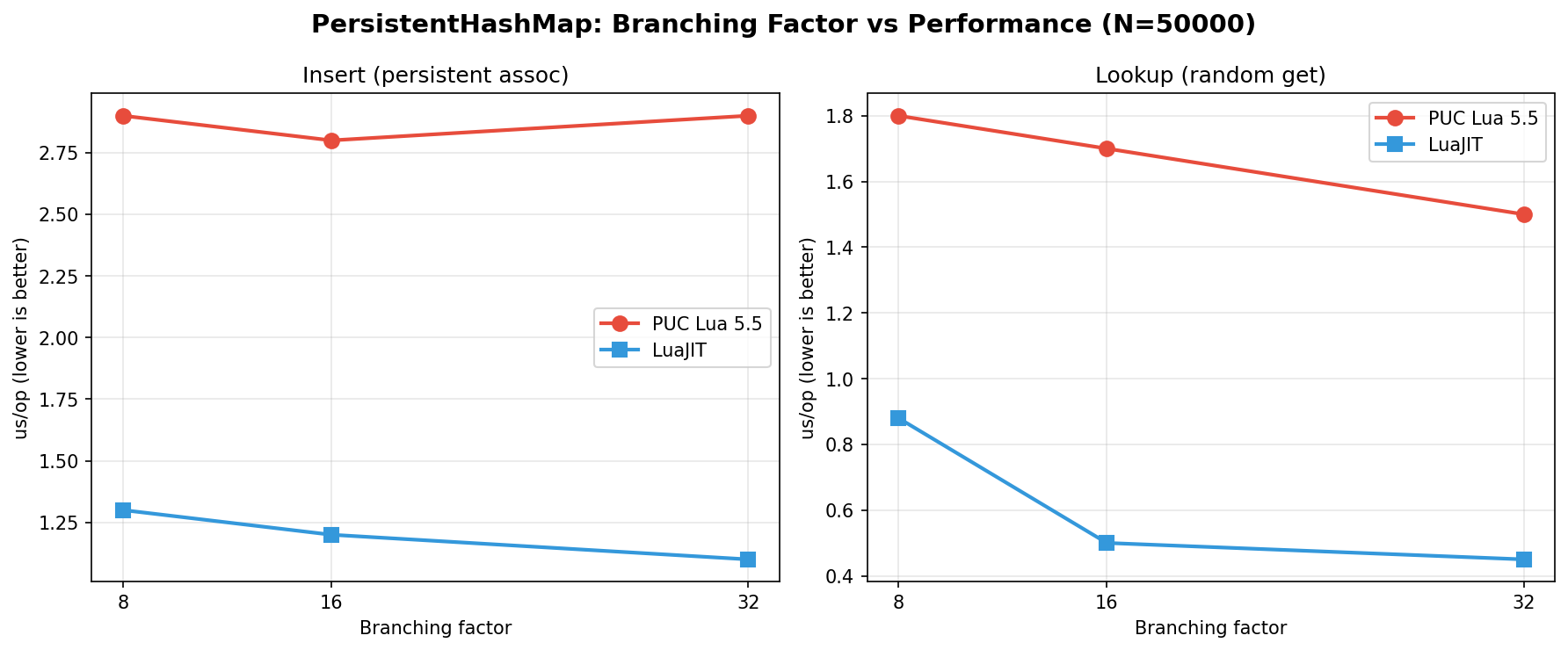
This is me testing how hash map branching factor affects operations. As can be seen, switching from 16 to 32 makes inserts slower on PUC Lua 5.5 but makes indexing faster. On LuaJIT both operations are faster.
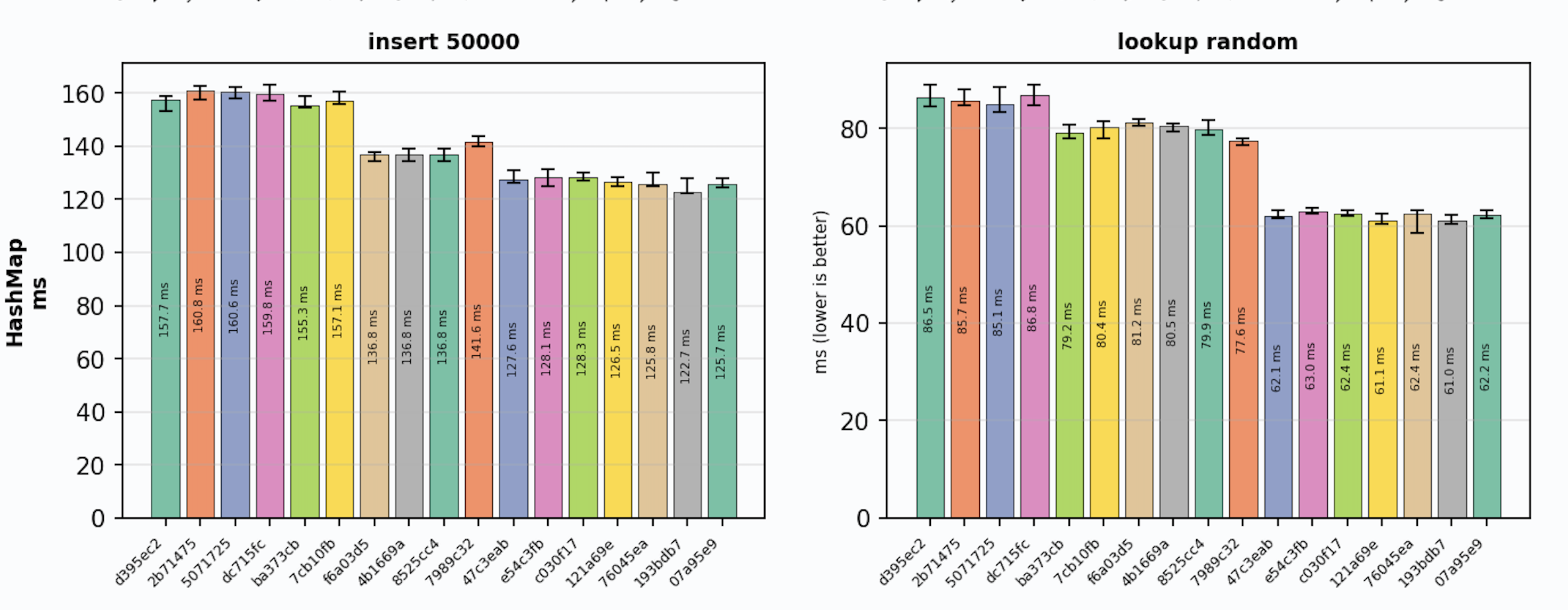
Looking at the charts, the 7989c32 commit with that change (the second orange bar) — insertions are slower than the previous commit, and indexing is faster than the previous commit.
Unfortunately, LuaJIT charts are noisy and I can’t confirm the speedup there.
Something to do with instabilities in the LuaJIT tracer, I guess.
Note I know, the results for some operations are worse than before all optimizations that took place. This is still a work in progress. Just shows how important relative measuring is.
The results are a mixed bag. Most operations that improved did so by only 1 or 2 milliseconds overall, meaning the per-operation cost is still quite high, compared to Lua tables. Yes, some became faster, so I’m keeping these changes, but I can also see that for some operations, they actually got slower than they were before any optimization work. The reason for that may be that I fixed a few bugs along the way. Anyway, I tried to prioritize transient collection variants, as they benefit most from optimizations given how they’re used, and LuaJIT performance where possible.
Some bars are not meaningful for certain operations. E.g., I had changes that had nothing to do with Persistent Vector, but affected it anyway, so this benchmark is still a bit flawed. At least those differences are within the deviation range.
Anyhow, just wanted to show that optimization is hard, and not all changes yield the results you expect. In the case of this library, I don’t think there are more low-hanging fruits to optimize, or at least I don’t see any. For example, there are a lot of table allocations that are hard to get rid of in the current implementation. A deeper analysis is needed, probably by people with more Lua knowledge.
I’m still satisfied with some improvements I got, but we’ll see if more are on the way.
Update
After a lot more benchmarks, flamegraphs, and throwing stuff at the wall, I think I can’t do much more. I decided to update this post instead of writing another one (and really should have waited before publishing the original) because at that point, I thought there was nothing more to do. Now I think there really isn’t. So the results are in:
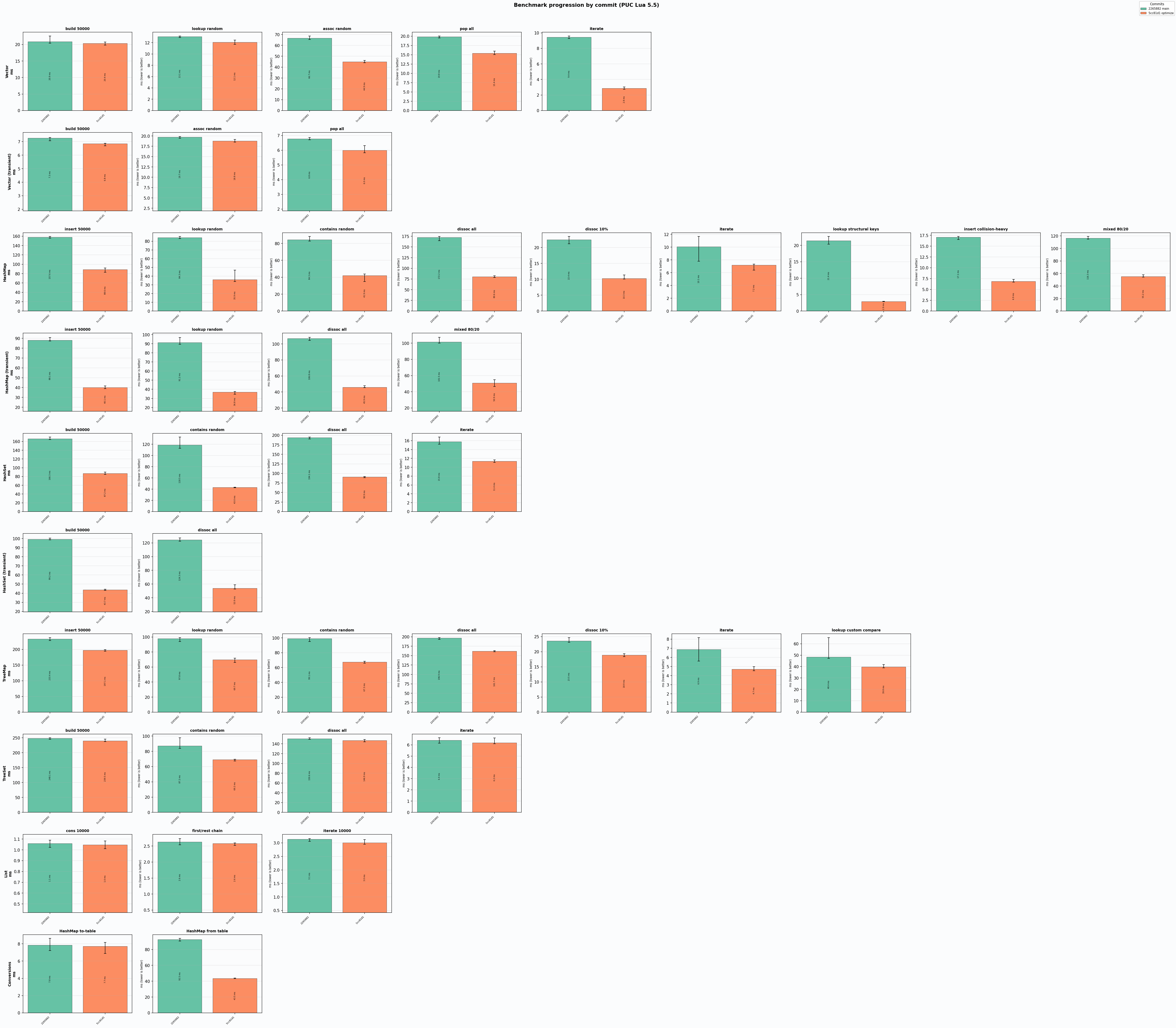
Figure 1: PUC Lua 5.5 (green - before, orange - after)

Figure 2: LuaJIT (green - before, orange - after)
As can be seen, the changes are more dramatic on Lua than on LuaJIT. Mostly because it’s hard to optimize for LuaJIT without sacrificing performance on Lua, so I re-prioritized Lua, since LuaJIT is already much faster.
The final benchmark tables are below.
PUC Lua 5.5
- PersistentVector
Operation Lua table Persistent ratio per op ratio (old) per op (old) build 50000 0.18 ms 18.88 ms 102x 0.378 us 119x 0.440 us lookup random 0.48 ms 11.44 ms 24x 0.229 us 28x 0.266 us assoc random 0.31 ms 42.72 ms 139x 0.854 us 222x 1.4 us pop all 0.14 ms 14.56 ms 106x 0.291 us 150x 0.415 us iterate 0.60 ms 2.74 ms 5x 0.055 us 17x 0.196 us
- TransientVector
Operation Lua table Transient ratio per op ratio (old) per op (old) build 50000 0.19 ms 6.55 ms 35x 0.131 us 41x 0.154 us assoc random 0.31 ms 17.64 ms 57x 0.353 us 67x 0.408 us pop all 0.14 ms 5.74 ms 42x 0.115 us 51x 0.142 us
- PersistentHashMap
Operation Lua table Persistent ratio per op ratio (old) per op (old) insert 50000 2.01 ms 81.44 ms 41x 1.6 us 82x 3.2 us lookup random 0.92 ms 34.03 ms 37x 0.681 us 81x 1.7 us contains random 1.82 ms 33.08 ms 18x 0.662 us 49x 1.7 us dissoc all 0.90 ms 76.97 ms 86x 1.5 us 187x 3.3 us dissoc 10% 0.18 ms 9.81 ms 56x 2.0 us 112x 3.7 us iterate 1.91 ms 7.22 ms 4x 0.144 us 4x 0.146 us lookup structural keys 0.14 ms 2.86 ms 21x 0.572 us 146x 4.1 us insert collision-heavy 0.13 ms 6.50 ms 51x 1.3 us 134x 3.5 us mixed 80/20 1.92 ms 53.67 ms 28x 1.1 us 62x 2.3 us
- TransientHashMap
Operation Lua table Transient ratio per op ratio (old) per op (old) insert 50000 2.02 ms 38.91 ms 19x 0.778 us 44x 1.7 us lookup random 1.14 ms 35.56 ms 31x 0.711 us 86x 1.7 us dissoc all 0.89 ms 44.52 ms 50x 0.890 us 112x 2.0 us mixed 80/20 4.39 ms 44.87 ms 10x 0.897 us 22x 1.9 us
LuaJIT
- PersistentVector
Operation Lua table Persistent ratio per op ratio (old) per op (old) build 50000 0.11 ms 8.12 ms 71x 0.162 us 84x 0.177 us lookup random 0.06 ms 0.67 ms 11x 0.013 us 11x 0.013 us assoc random 0.04 ms 22.91 ms 559x 0.458 us 731x 0.585 us pop all 0.02 ms 10.77 ms 718x 0.215 us 657x 0.210 us iterate 0.02 ms 0.23 ms 12x 0.005 us 26x 0.011 us
- TransientVector
Operation Lua table Transient ratio per op ratio (old) per op (old) build 50000 0.05 ms 0.79 ms 16x 0.016 us 12x 0.012 us assoc random 0.04 ms 2.22 ms 55x 0.044 us 28x 0.022 us pop all 0.02 ms 0.35 ms 23x 0.007 us 50x 0.016 us
- PersistentHashMap
Operation Lua table Persistent ratio per op ratio (old) per op (old) insert 50000 0.79 ms 32.32 ms 41x 0.646 us 50x 0.989 us lookup random 0.34 ms 5.78 ms 17x 0.116 us 43x 0.248 us contains random 0.30 ms 5.91 ms 20x 0.118 us 40x 0.257 us dissoc all 0.23 ms 27.02 ms 119x 0.540 us 191x 0.894 us dissoc 10% 0.05 ms 5.89 ms 118x 1.2 us 121x 1.4 us iterate 0.07 ms 1.07 ms 16x 0.021 us 30x 0.040 us lookup structural keys 0.02 ms 2.41 ms 121x 0.483 us 119x 0.498 us insert collision-heavy 0.28 ms 5.20 ms 19x 1.0 us 36x 1.2 us mixed 80/20 0.50 ms 46.59 ms 94x 0.932 us 40x 0.513 us
- TransientHashMap
Operation Lua table Transient ratio per op ratio (old) per op (old) insert 50000 0.91 ms 30.92 ms 34x 0.618 us 11x 0.242 us lookup random 0.32 ms 34.90 ms 110x 0.698 us 44x 0.246 us dissoc all 0.23 ms 36.35 ms 162x 0.727 us 57x 0.271 us mixed 80/20 1.29 ms 40.71 ms 32x 0.814 us 11x 0.309 us
Conclusion
Yes, the benchmark shows that some operations slowed down, some sped up. Ideally, I’d like to have no slowdown, but that’s that. Still, I wouldn’t trust my LuaJIT benchmark, though - graphs show that for some weird reason unrelated changes affect performance in the modules not touched by those changes at all. So these changes are now merged into the main branch.
Main bottleneck now is table allocation and array copying - things I already spent optimizing a lot of time with mixed results. So I think I can’t do better than that. At least without major algorithmic restructuring.
With that, the next post should be about the compiler.