Effects of Slow and Fast systems
Modern-day computing is fast. Incredibly fast! For most tasks, the feedback can be considered instantaneous. Even the slowest languages used in production, like Python, are considered fast enough for the majority of tasks, and if not, there are almost always faster alternatives you could choose from.
Modern-day CPUs are speedy boys indeed, but it’s not just CPUs that are great. RAM too is no longer a major bottleneck both in terms of size and speed, and even storage is incredibly fast. GPUs can do millions of tasks under a millisecond in parallel. Hardware these days is purely amazing.
Because it’s so great, software engineers can do their job much more comfortably, choosing languages with nicer abstractions, and quality-of-life features like automatic garbage collection. Sometimes, a small trade-off in execution speed is massively outweighed by the robustness that managed languages provide. I myself am a big fan of advanced virtual machines like the JVM and LuaJIT - they can be both incredibly fast and give you a lot of freedom of expression.
However, this wasn’t always the case. In the old days, computers were slower. Incredibly slower! Today’s CPU can process lots of instructions per second. The execution speed is usually measured in MIPS - Million Instructions Per Second. For instance, 2021 Intel Core i7 346,350 MIPS - three hundred forty-six billion three hundred fifty million instructions per second, running at 4.92 GHz frequency. In 1978 Intel 8086 could only process 330,000 instructions per second running at 5.000 MHzsource.
We all know this story, about Moore’s law, that the number of transistors in an integrated circuit doubles about every two years, and how it is slowed in around 2010. But while it was going strong, computers became faster and faster every few years. Computer efficiency is another thing that improved over the years:
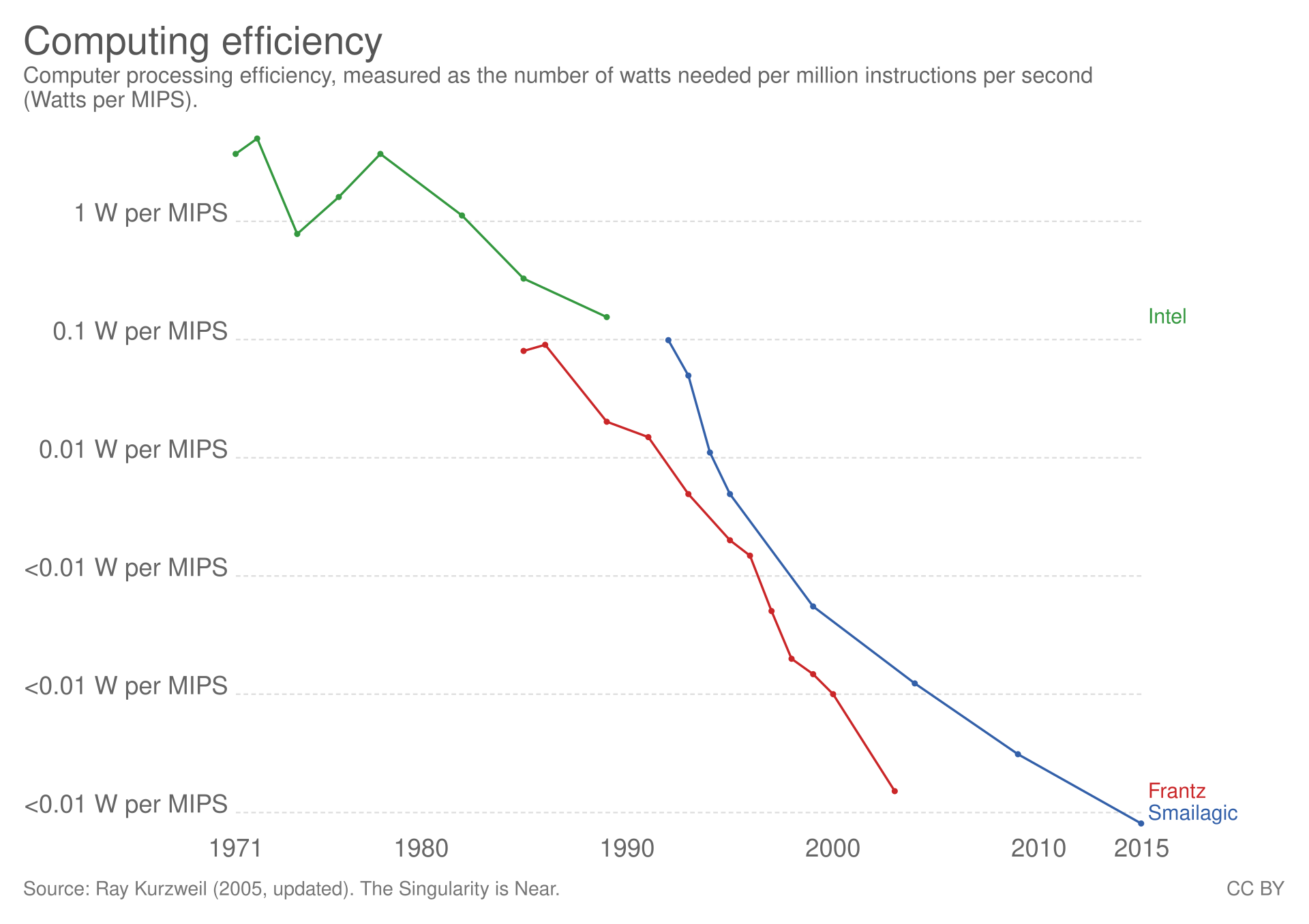
Figure 1: Computer processing efficiency, measured as the power needed per million instructions per second (watts per MIPS)
Perhaps, you already understand, where I’m going with this. Hardware has gotten so much faster over the years we no longer have to wait for the majority of tasks to be completed. Consequently, the feedback loop for software development shortened dramatically. So today I want to talk about the implications of working with horribly slow and incredibly fast systems.
Fast systems
First, a word about the term “system” I’m using for this post. I’m not talking about operating systems, rather I use this term more broadly. A particular language can be a system in the context of this text. Or an entire environment starting from your personal machine, network, remote server, and your tooling of choice and workflow revolving around all of this can also be considered a system here. Or more broadly - a system is something you interact with systematically.
So let’s look at a few fast systems and implications of their use.
Interactive coding
I’m a Clojure programmer. So I have a high value for fast feedback during the development process - I can run code in the REPL at any time and immediately see the effect applied to my running application. This makes fixing most of the bugs a breeze.
I’m a backend developer, so most of my code runs on a server, not on my machine. If I were using something else, like Scala or Java, my typical workflow for fixing a bug would probably be:
- Identify a possible wrong place in the codebase
- Change it
- Compile the project
- Deploy it to the remote server1
- Restart the service
- Try to reproduce the bug on a running system
- If the bug is not fixed Goto 1
- You’re good
With Clojure, my workflow is a bit different:
- Set up SSH port forwarding to the remote server
- Connect to the running application via remote REPL
- Identify a possible wrong place in the codebase
- Change it
- Try to reproduce the bug on a running system
- If the bug is not fixed Goto 3
- Compile the project
- Deploy it to the remote server
- Restart the service
- You’re good
While it is a bit longer overall, the feedback loop itself has only three steps, compared to six in the former case. Thus, I would say that Clojure is a faster system than Scala or plain Java thanks to the REPL2 and the ability to change running programs remotely. The fact that I don’t have to wait for compilation, deployment, service restart, and possibly manually setting up some state for bug reproduction after each restart, makes feedback much more immediate. Thus, I can make almost arbitrary and quite small changes and experiment with real data on live applications until I get things right. That’s what fast systems are good for.
Notebooks
Ok, so REPL, while being interactive and fast is not the pinnacle of interactivity. Notebooks, for example, also give you immediate feedback, while also providing a UI for changing the parameters of your computation:
While this concrete example is kind of slow to respond, it is still a nicer way to get your results faster by dragging a slider instead of changing code directly. I like the idea of reproducible research papers, where the document itself is the program, I even made something like that with Org Mode in Emacs and Lua via LÖVE2D. It wasn’t as interactive, as all of the images are static and require changing the parameters and re-evaluation in the document, but I think it would be possible to make a web version of it by rendering to HTML and connecting to the LÖVE via REPL.
But why stop there? Bret Victor years ago showed us an interactive notebook where not only code is interactive, but the results of it are as well! You can see it for yourself in the talk Inventing on Principle.
LLM-assisted coding
Finally, AI.
Yes, we’re going to talk about LLM-assisted programming, or so-called vibe coding. I consider it another fast system, because you can get your code changes pretty fast by giving your code to some LLM, and it will spit out a solution for you. Either incremental changes to your code or additional code written based on your program’s context.
This also makes your feedback loop shorter, because you don’t have to write the code yourself. You can think in higher-order terms, and LLM will hopefully give you what you need. In the best-case scenario, you won’t even touch the code by yourself.
I think combining Bret Victor’s notebook-like system with LLM can be an interesting approach. Actually, the code for the square wave example above was written by a Claude 3 Haiku model3. I have mixed thoughts on AI and LLM in general, but we’re gonna leave it out of the scope of this topic.
Fast knowledge system
Another thing about LLMs is that it is a very compelling search engine that can find information really fast. Want to learn a new thing? Ask the LLM about it and it will spit out the essential information. The quality of such information is a subject for another time, but let’s assume that it doesn’t hallucinate too much.
You can learn things fast! If the thing you’re trying to learn is well covered in the training data, it can be much faster than learning from the books. Especially because a well-trained LLM can answer your questions and provide more examples, unlike any plain ol’ book.
Slow systems
Now let’s talk about slow systems. Slow here can mean many things, from the amount of time it takes to do something to the general approach to doing something.
Slow hardware
I started this post by talking about hardware advancement for a reason.
At the university, my computer science teacher always said that programmers should get the slowest hardware they can find, and do all of the development on it. He reasoned that if an application can be developed and tested on slow hardware, the end-user experience will be great because their machines would certainly be faster than the ones that were used for development.
Developing on slower hardware limits you in a way that is hard to get otherwise. Today’s computers can process a lot of data fast, but three decades ago it wasn’t possible. Yet, we could go to the cinema in 1995 and watch such films as Toy Story - a film that was fully CGI. It took four years to make the film, and a lot of it was just rendering. Two years earlier, in 1993 Jurassic Park came out, and while it contained a very small amount of computer graphics, a test scene for the film was made before featuring fully computer-generated dinosaurs. The thing is, each frame took around 12 hours to render back then. And today we get video games that can look almost photo-real, outputting more than 60 frames in a single second.
What a horrible time the 90s were for CGI, you might say, and while you’d be right, slow hardware also had a positive effect - people had to write extremely fast software to even get barely usable results. And this software had to be robust too. When computing is this slow, you can’t avoid making a mistake, ruining days or even months of work.
But today it’s not a problem, right? Hardware is always fast, and we can upgrade it any time.
Well, not quite. While computers have become faster, we still have slow hardware that people have to optimize hard for. Want to try and take a guess which is it?
Game consoles.
Yeah, right, the thing that is supposed to be a pinnacle of gaming and graphics on release date slowly becomes obsolete with each year of its life. New CPUs and GPUs come out every few years, but game developers still have to optimize games for a console that is already a few years old.
Take a look at early games for Super Nintendo and the late games released for it. The later games are much more graphically rich than the early ones because while the hardware got older, the ambitions for games only got higher. And developers had to optimize, even use dirty tricks to pump out graphics like in Super Metroid, for example.
Or take PlayStation 3. Some of its late exclusives looked even better than the ones released for PlayStation 4 at launch. Why? Because their development started when PlayStation4 was not available, and gamers were getting better and better graphics on their PCs, so PlayStation 3 had to compete with them, not just other consoles. And slow hardware meant that they couldn’t just slap a new Unreal Engine on and expect it to just work - they had to optimize their games for a specific, and somewhat arcane hardware. And how good these late games looked, especially compared to the launch titles!
Today we have a problem with a lot of games that release on several platforms at once because game developers often use the top tier hardware for their development process, and then games can’t run smoothly on hardware with lower specs that it wasn’t optimized for specifically. Had the developers restricted their hardware limit to the lowest common denominator platform they’re targeting,f and thus the urge to optimize their code, maybe consumers could upgrade their hardware less often too, and be happier overall.
And this isn’t just games. Ordinary software today is as slow as ****. Like, some time ago the GNOME project replaced their old image viewer with a new one, and its startup time is seemingly ten times slower. And once it started it couldn’t even switch pictures as fast as the old one. I don’t know what kind of computers GNOME developers use, but it seems that lower-spec hardware is not their target. And don’t get me started comparing modern GNOME’s speed with GNOME24.
Microsoft Windows sometimes takes a few seconds to show me the menu when I right-click on the desktop. This is the most basic action you can do, and yet it is so slow. Maybe if I had a gaming PC with a top-tier CPU, GPU, RAM, and SSD, it would not be so slow, but all I have is a late 2019 laptop with an eight-core AMD Ryzen 7 3750H. And it packs enough power for almost everything I do, even though it is six years old.
Slow tools and workflows
When your hardware is slow, all of your tools are as fast as your hardware allows them to be. And when you have a slow tool, you don’t want to run it more times than is necessary, because you have to wait every time.
This also applies to workflows. If your workflow is slow, you don’t want to take unnecessary steps, as it would take your precious time. Going back to the Interactive coding section of this post, let’s again look at the workflow for Scala/Java software development:
- Identify the correct place in your codebase to start working
- Write code
- Compile the project
- Deploy it to the remote server
- Restart the service
- Try to see if it works
- If it doesn’t work right goto 2
- You’re good
Again, compared to a language with interactive development, like Clojure, it is several steps longer. The implication of this is that you should, in theory, spend more time thinking about how to approach the task at hand. You don’t want to repeat this scenario over and over making small incremental changes, because compilation, deployment, restarting, and testing take too much time. So in theory, you should always try to write your code as best as you possibly can.
This, indeed is what happened in the early days of computing. Back then, computers operated via punch cards, and people had to submit their code on paper to the card puncher operator, then wait in the queue of other researchers, finally receiving the results printed out by the machine on another piece of paper. The cost of a mistake in the code was so high, that programmers had to spend a lot of time verifying their code in their head and praying that the operator wouldn’t make a typo while transferring your code to the punch card. The process demanded quality.
Only later we got machines that could do this in a fraction of time, but it was still slow. You may be familiar with “The Story of Mel, a Real Programmer”. The gist of it was that the machine was using a drum memory, which was very slow, but instead of accepting it as fact, Melvin Kaye, the protagonist of this story wrote its code in such a way that the program self-modified itself in the time it takes for the drum to revolve, to immediately continue. This is what basically an optimizing compiler would do, but Mel didn’t like the fact that this compiler would produce ugly code, and was still slower than a hand-optimized one. Somehow, we’ve lost this art of coding, but that’s another story.
Going back to slow workflow, we no longer suffer from waiting in the queue to use the computer, but maybe we should? There’s a saying that urgent things are rarely of great importance, and those that are important are seldom of great urgency. Sometimes it’s good to take your time and go and take a seat, thinking about the problem you’re solving, and how to solve it well, or even leave it to the subconscious thinking and step away from it entirely5. The dread of waiting in the queue for several days can easily force you into such behavior.
Slow knowledge system
In the AI section I’ve touched on the learning aspect of using LLMs. While you indeed can get a lot of information fast, sometimes it’s better to take it slow. Slow learning is not bad, if you’re digging deep.
Sometimes, when I’m learning a new thing, I find myself reading books, sometimes even several times. By the time I’ve finished, I have a deep understanding of the subject and can reason about it much more thoroughly than I ever could if I just did a quick search or used an LLM to explain stuff to me. I like the education model at the university - you have lectures that go over the subject in some depth, but then you’re given time to go over that same subject at your own pace with a book at home. That first quick overview gave you enough context to understand a longer-form explanation usually reserved for books so that you have an easier time understanding it. It takes a lot more time because you have to go over the same material basically twice, but your understanding is far more deep as a result. If you’re a good student, that is. I wasn’t, and now I’m sad about it.
Before the internet, the only way of acquiring knowledge was by going to a library. If it had the book, then great, but that’s all you get. If not - tough time, maybe you could afford to go to another town with a bigger library, or maybe you could request for your library to acquire a specific book, but that’s it. Today we can get our hands almost at any book we want.
But this isn’t an all-good thing either. Too many books in our reach can be overwhelming by itself. Sometimes, I think, it’s best when our choice is limited, and if we want to go out of our way to get another book, it is usually because we know that we need it, not because we’re bored with the one we have.
Effects of Slow and Fast systems
Times of slow computing are long gone. But the effects of slow systems are not limited to computing - it’s everywhere. The term system, I used in this article, is a lot wider, and applies to a lot of things. But today, more faster and faster systems are appearing around us. This already had an effect on our life.
For example, long-form content became a rare thing, because our brains have adjusted to the fast form of content consumption, and a lot of people today can’t hold their attention for longer than a minute, sometimes less. A book is a slow system, a course is a faster system, and an article is an even faster one. They all serve the purpose of providing information.
I write pretty long posts myself, and I noticed that because it takes a lot of time to write everyone, my attention span improved over these five years of writing. My workflow is also slow, as I don’t have things like live preview of my blog posts, I don’t use any automation tools or LLMs, just a basic spellchecker. Because I re-read my posts a lot, it improved my ability to concentrate - I became able to concentrate more, and now I can read more than I could earlier as a result.
Old paper mail is a very slow system, engaging longer and more thoughtful forms of conversation. You wouldn’t write “Hi! I have a question” in a mail, and expect a “Hi! What’s your question?” as a response. Email is a faster system, but still a rather slow one, when compared to more modern chats. But a lot of people today have forgotten how to write long and concise messages because faster systems have been around for so long.
I have high respect for communities, where people can respond to each other with thoughtful thought heavy messages. That’s also the reason I’m using email as a comment system for my blog - I doubt many people would want to write a long comment to my post if it was a web form, but when given an email as the feedback system, they subconsciously try to give it more thought.
Don’t get me wrong though, I’m not advocating that we should abandon advancements in hardware and infrastructure and go to simpler times. No, of course not! I too enjoy faster systems, I like interactive programming, fast feedback, and such. I have a lot of fond memories of late-night chatting in fast-paced group chats, and I definitively don’t want all of my communication to be done via email only. Sometimes I want to ask about things I know nothing of, instead of searching through books or papers. I just think that sometimes slowing down is the thing you need, but we rarely think about it. When everyone around you is all about “Go! Go! Go!”, it is tough to rise and say “Hold on, I need to take it slow”.
-
It’s not a production, but a test server. ↩︎
-
I know that Scala REPL is a thing, but nobody in our team uses it like this. ↩︎
-
Not that I couldn’t write it myself, I just don’t know how to use Jupiter and am not familiar enough with Python’s matplotlib. ↩︎
-
Even though GNOME got a lot faster over the years since the original GNOME Shell release. ↩︎